20 ROAR-Written-Vocabulary External Validity & DIF Results
20.1 External Validity (grades 3-5)
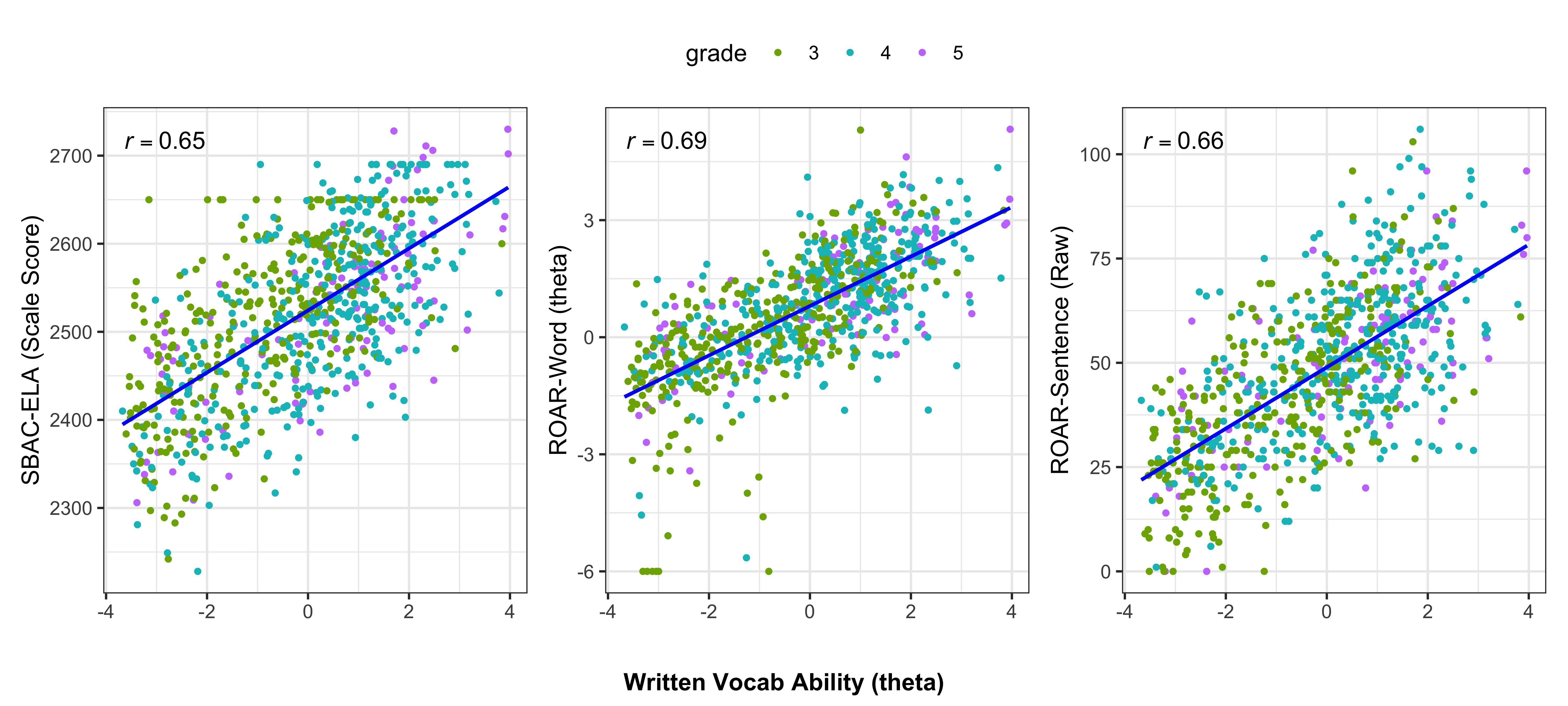
To examine the external relationship between the ROAR-Written-Vocabulary assessment and other reading-related measures, we used a subset of sample (n = 810 students) who provided the ELS scores from the statewide standardized assessment (SBAC, Smarter Balanced Assessment Consortium) and scores from two other ROAR measures: ROAR-Word and ROAR-Sentence. These students were in grades 3-5 in public schools in California.
Figure 20.1 below shows the bivariate relationship between ROAR-Written-Vocabulary (in logits), on the x-axis, and one of the other assessments, namely, SBAC-ELA scale scores, ROAR-Word (in logits) and ROAR-Sentence (raw score). As expected, ROAR-Written-Vocabulary showed moderately-high correlations with these external measures: the highest correlation was observed with the ROAR-Word measure (r = 0.69), followed by the ROAR-Sentence (r = 0.66) and SBAC-ELA scores (r = 0.65). This finding provides evidence for concurrent validity, demonstrating that ROAR-Written-Vocabulary measures skills that are meaningfully related to broader reading achievement as assessed by the state ELA standardized test and other reading-related measures.
20.1.1 Predictive Power of ROAR-Written-Vocabulary
To determine whether ROAR-Written-Vocabulary has explanatory power beyond the other two ROAR measures in predicting SBAC-ELA scores, we conducted multiple linear regression analyses. Four models were run, all predicting SBAC-ELA scale scores with various combinations of ROAR measures, using student grade level as a control variable (with grade 3 as the reference category).
The results, shown in Table 20.1, demonstrate that all three ROAR measures have unique and statistically significant effects on SBAC-ELA scores after controlling for other predictors. This is indicated by the positive coefficient estimates and associated p-values shown in the M3 column. The explanatory power of ROAR-Written-Vocabulary increased by approximately eight percentage points when it was added to a model already containing the ROAR-Word and ROAR-Sentence measures (adjusted \(R^2\) increased from 0.44 in M2 to 0.52 in M3). This increase was statistically significant, \(F(1, 804) = 127.24, p < .001\). These results suggest that ROAR-Written-Vocabulary captures unique aspects of reading ability that contribute to comprehension beyond what is measured by word- and sentence-level ROAR-assessments.
| M0 | M1 | M2 | M3 | |||||
| Predictors | Estimates | p | Estimates | p | Estimates | p | Estimates | p |
| Intercept | 2508.78 | <0.001 | 2526.49 | <0.001 | 2530.34 | <0.001 | 2536.93 | <0.001 |
| grade 4 | 15.77 | 0.026 | -12.79 | 0.028 | -19.45 | <0.001 | -30.03 | <0.001 |
| grade 5 | 10.70 | 0.298 | -19.73 | 0.018 | -24.81 | 0.002 | -36.28 | <0.001 |
| ROAR-Word (z-score) | 58.03 | <0.001 | 33.02 | <0.001 | 16.67 | <0.001 | ||
| ROAR-Sentence (z-score) | 36.48 | <0.001 | 23.76 | <0.001 | ||||
| ROAR-Written-Vocabulary (z-score) | 38.59 | <0.001 | ||||||
| Observations | 810 | 810 | 810 | 810 | ||||
| R2 / R2 adjusted | 0.006 / 0.004 | 0.369 / 0.366 | 0.444 / 0.441 | 0.520 / 0.517 | ||||
20.2 Faireness
To evaluate the fairness and measurement invariance of the ROAR-Written-Vocabulary assessment, a Differential Item Functioning (DIF) analysis was conducted to identify items that may function differently for students of equal ability based on gender. In this analysis, we used female as the reference group and male as the focal group. We used a subsample of 3,716 students in grades 1-12 whose gender identification was available from the administrative records (see Table 18.1 and Table 12.2 for the grade and race/ethnicity distributions of this sample).
Separate Rasch models were fitted for each group using the mirt (Chalmers 2025) and robustDIF (Halpin 2024) packages to extract group-specific item difficulty parameters (intercepts) while minimizing the influence of outlier items that might otherwise skew the overall scale.
Following standard psychometric practice, the observed logit differences between groups were converted to the Educational Testing Service (ETS) Delta scale using a constant of 2.35. Items were then classified into three categories based on the magnitude of the effect: Category A (Negligible), Category B (Moderate), and Category C (Large) (Zwick, Thayer, and Lewis 1999). This categorization allows for a prioritized review of items where secondary dimensions—such as context-specific vocabulary or cultural associations—may interact with gender independently of the primary trait being measured.
As can be seen in Table 20.2, two items (standard and immediately), out of the 89 items, had a large DIF, one favoring male and the other favoring female. Additionally, eleven items were found to have a moderate DIF, two disadvantaging female and nine disadvantaging male. These items were flagged for content review for potential revision or removal to ensure continued test equity and validity.
| Target Word | Logit Diff | ETS Cat | Harder For | Item Stem | Key | Distractor1 | Distractor2 | Distractor3 |
|---|---|---|---|---|---|---|---|---|
| standard | 0.82 | C | female | It is standard for workers to sit during meetings, but meetings where everyone stands are becoming popular. | usual | strange | best | required |
| immediately | 0.66 | C | male | The coach wanted an answer to the question immediately. | quickly | finally | easily | clearly |
| features | 0.63 | B | male | Race cars today have many safety features like strong frames and safety tools. | parts | plans | uses | rides |
| items | 0.51 | B | male | Food and other items made with natural things break down and become part of the soil. | objects | resources | terms | forms |
| efficient | 0.52 | B | female | The new manager wanted to make the factory more efficient. | productive | important | expensive | convenient |
| distinct | 0.56 | B | female | The car's distinct color made it easy to find in a crowded parking lot. | unique | pure | bright | faded |
| selection | 0.46 | B | male | The coach praised the team for their selection of Luke as captain. | choice | support | trust | aid |
| formal | 0.44 | B | male | The visiting teacher gave a formal speech before answering questions from the students. | proper | brief | fine | public |
| property | 0.54 | B | male | The family moved into a property with big bedrooms. | home | farm | store | office |
| associated | 0.48 | B | male | The moon is associated with night and dreams in many stories. | linked | named | darkened | covered |
| frequently | 0.45 | B | male | The family frequently traveled to national parks in the summer. | often | mainly | safely | quickly |
| required | 0.45 | B | male | The school leaders said that homework was required every day. | needed | made up | seen | sent |
| equipment | 0.43 | B | male | We went to the store to get the equipment we needed to plant the seeds. | resources | attention | water | flowers |
20.3 Discussion
20.3.1 Reliability and Validity Evidence
The ROAR-Written Vocabulary assessment demonstrates strong psychometric properties, providing a robust measure of the latent vocabulary construct. With a person separation reliability of 0.82 and an EAP reliability of 0.85, the instrument effectively differentiates between students of varying ability levels, supporting its use for individual-level assessment and progress monitoring.
Evidence for construct validity is provided by the alignment of item difficulties with student ability. The Wright Map (Figure 19.3) confirms that the assessment covers a broad range of the latent construct, particularly for students in the upper elementary through high school grades. The item hierarchy follows a logical progression of linguistic complexity, from high-frequency academic words (e.g., security, effort) to more specialized or abstract vocabulary (e.g., consists, quoted).
External validity evidence is further supported by strong correlations with established benchmarks. ROAR-Written Vocabulary demonstrated significant convergent validity with the SBAC-ELA (r = 0.65) as well as with ROAR-Word (r = 0.69) and Sentence (r = 0.66) subtests. Importantly, regression analyses revealed that ROAR-Written Vocabulary accounted for a unique 8% of the variance in SBAC-ELA scores, even after controlling for word- and sentence-level skills. This unique contribution reinforces theoretical models of reading which posit that academic vocabulary knowledge is a distinct and essential component of the reading system, providing explanatory power for comprehension that is not captured by foundational decoding or syntactic processing alone.
20.3.2 Limitations
Despite strong psychometric results, several limitations should be noted. While large in number, the calibration relied on a convenient sample (n = 4,638), with about 40% students in California and 23% in Colorado, limiting generalizability.
The current item pool, though sufficient for calibration, lacks coverage at the lower end of the ability distribution, resulting in a visible “floor effect” for the lowest-performing students in Grades 1–5. This is a structural reflection of the assessment’s grounding in core academic vocabulary (Hiebert et al., 2018). The ROAR-Written Vocabulary assessment specifically targets the ~2,500 morphological word families that constitute the lexical foundation of academic discourse across grades 1–12 (Gardner and Davies 2014; Hiebert, Goodwin, and Cervetti 2018).
Because the ROAR-Written Vocabulary is designed to measure this specific core academic vocabulary knowledge, the easiest items (e.g., security, effort) represent the lower boundary of that academic tier. While adding high-frequency oral vocabulary (e.g., dog, run) would increase measurement precision for low-ability students, it would deviate from the intended construct of academic lexical knowledge. Consequently, the observed floor effect indicates that these students are likely to have not acquired the essential lexical foundation necessary to navigate the vast majority (91–97%) of academic texts they encounter in school. Further investigation is required to confirm the longitudinal and functional implications of these findings.
While differential item functioning (DIF) by gender was examined, additional fairness and measurement invariance analyses are needed. Thirteen of the 89 items (15%) showed gender-DIF, pointing to the need for careful content review and monitoring. Further research should examine other subgroups by English learner status, socioeconomic status, disability, and rate/ethnicity.
Finally, the cross-sectional nature of this study limits inferences regarding the developmental trajectory of vocabulary knowledge over time. Future longitudinal research is required to validate the assessment’s sensitivity to developmental gains and its efficacy as a progress-monitoring tool.
20.4 Future Directions
To provide full coverage of the targeted academic lexicon, a primary goal for future development is the generation and calibration of items representing all 2,500 morphological word families identified in the core vocabulary framework (Hiebert, Goodwin, and Cervetti 2018). Given the scale of this task, we are exploring the use of Generative AI to replicate the specific linguistic and design features of the ROAR-Written Vocabulary assessment. By formalizing the human-validated design procedures into an AI-supported workflow, we aim to build a comprehensive, high-precision item bank that remains perfectly aligned with the theoretical and empirical foundations of the core vocabulary framework.