| group | category | reliability | n.stdts |
|---|---|---|---|
| el_status | EL | 0.86 | 104 |
| el_status | non-EL | 0.83 | 563 |
| gender | F | 0.85 | 371 |
| gender | M | 0.86 | 343 |
| grade | 2 | 0.88 | 314 |
| grade | 3 | 0.80 | 143 |
| grade | 4 | 0.84 | 125 |
| grade | 5 | 0.84 | 135 |
| primary_lang | English | 0.84 | 388 |
| primary_lang | non-English | 0.85 | 279 |
| sped | non-sped | 0.84 | 653 |
| sped | sped | 0.90 | 14 |
13 ROAR-Morphology Calibration/Validation Results
The Rasch Model (Rasch 1993) was used to calibrate the ROAR-Morphology response data, using the test analysis module (TAM, ver. 4.2-21) package (Robitzsch et al. 2024) in R. All items were dichotomously scored (1 = correct, 0 = incorrect). The mean of (ability) was fixed to 0 for model identification. This allows for the placement of both items and students on the same interval scale, facilitating interpretation of student performance relative to item difficulty on the Wright map.
13.1 Model Fit
We first examined how well the Rasch model fit to the response data through the mean-square fit statistics.The infit values ranged from 0.79 to 1.22, which are all within the acceptable range (0.75-1.33, Adams and Khoo 1993). This means that the items fit well to the Rasch model: observed responses are not overly predictive nor too random with respect to the model predictions.
13.2 Reliability
Person separation reliability was found to be 0.854, which demonstrates how well the measure spreads students along the ability continuum and differentiates them in the target construct (Wright and Masters 1982). This is analogous to Cronbach’s alpha and suggests that examinees can be separated into approximately three strata (Fisher 1992).
EAP (expected a posteriori) reliability, also known as marginal reliability, was found to be 0.89. accounting for the precision of ability estimates across the entire ability distribution. Both reliability indices exceed a common threshold (0.80 or higher), demonstrating that ROAR-Morphology accurately measures the intended construct, and the measurement results reflect genuine differences in morphological ability rather than measurement error.
Reliability for Sub-Groups To ensure that ROAR-Morphology is a fair and equitable assessment across different demographic groups, we report reliability separately by different groups in Table 13.1. Reliability is 0.80 or higher for all subgroups.
This reliability was calculated as:
\[ \text{Reliability} = 1 - \frac{\mathrm{mean}(SE^2)}{\mathrm{Var}(\hat{\theta})} \]
- \(mean(SE^2)\) is the average of the squared standard errors across students, and
- \({Var}(\hat{\theta})\) is the observed variance of the ability estimates.
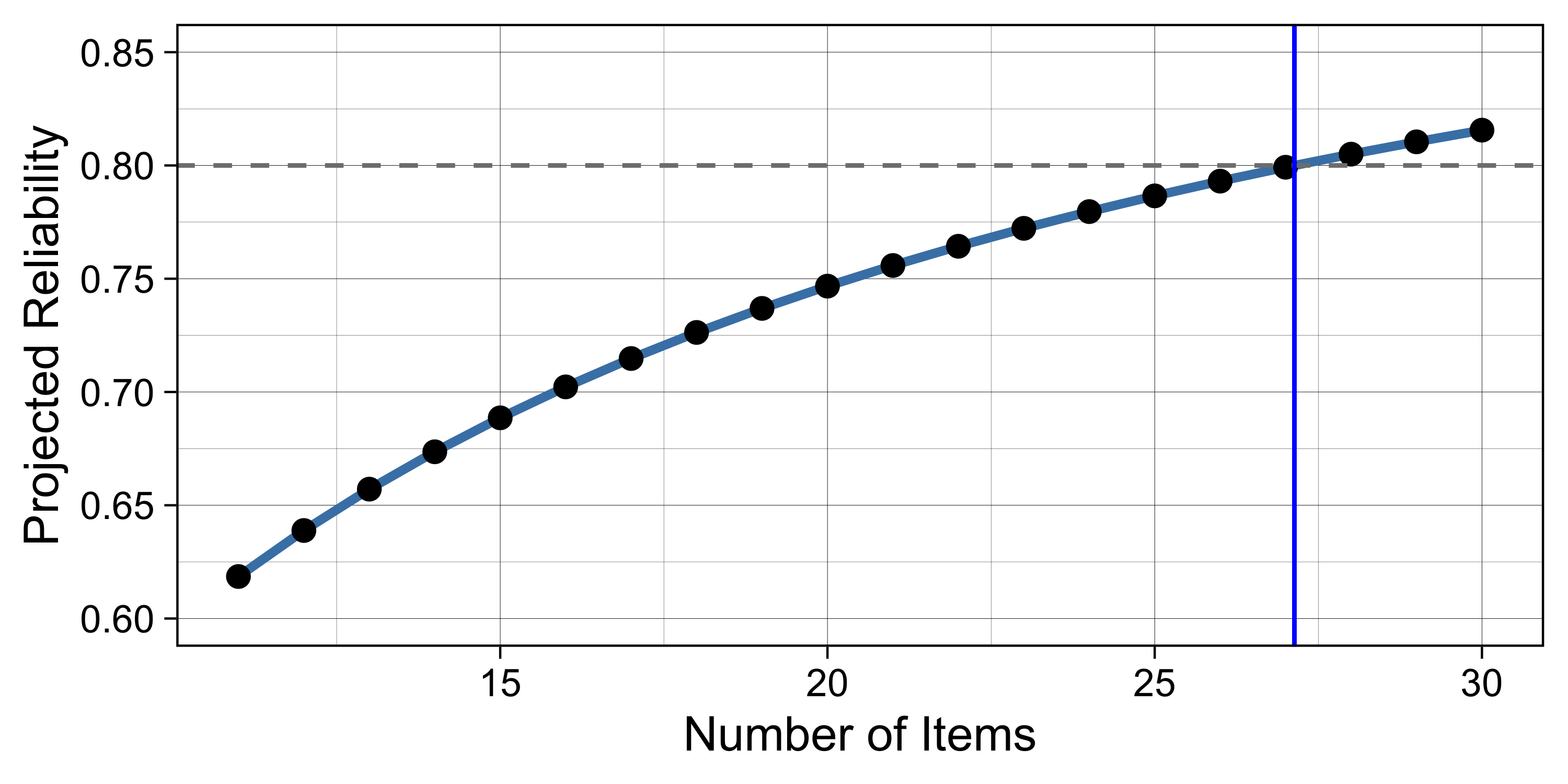
Number of Items & Reliability We grouped students by the number of items attempted and computed the reliability for each group. Table 13.2 below shows the empirical results. The table indicates that ~30 items are needed to reach the reliability of .80, if we use the fixed form (without a computer-adaptive algorithm).
| num_items | reliability | n.stdts | mean_SE2 | var_theta |
|---|---|---|---|---|
| <20 | 0.64 | 7 | 0.48 | 1.33 |
| 20-29 | 0.78 | 12 | 0.51 | 2.37 |
| 30-34 | 0.82 | 15 | 0.36 | 2.03 |
| 35-39 | 0.89 | 19 | 0.21 | 2.02 |
| 40 | 0.85 | 664 | 0.31 | 2.14 |
Projected Reliability Figure 13.1 shows the projected reliability based on the Spearman-Brown formula. It turns out that 27 items are needed to achieve the reliability of 0.80, if we use the fixed form. We expect that with ROAR’s computer adaptive algorithm, much fewer items will be needed.
13.3 Construct Validity
Validity refers to the degree to which evidence supports the intended interpretations and uses of assessment scores. For ROAR-Morphology, we examined multiple sources of validity evidence to ensure the assessment accurately measures morphological knowledge and supports appropriate educational decisions. This section presents construct validity evidence through analysis of the assessment’s internal structure, followed by external validity evidence examining relationships with other measures.
13.3.1 Support for Hypothesized Construct Structure
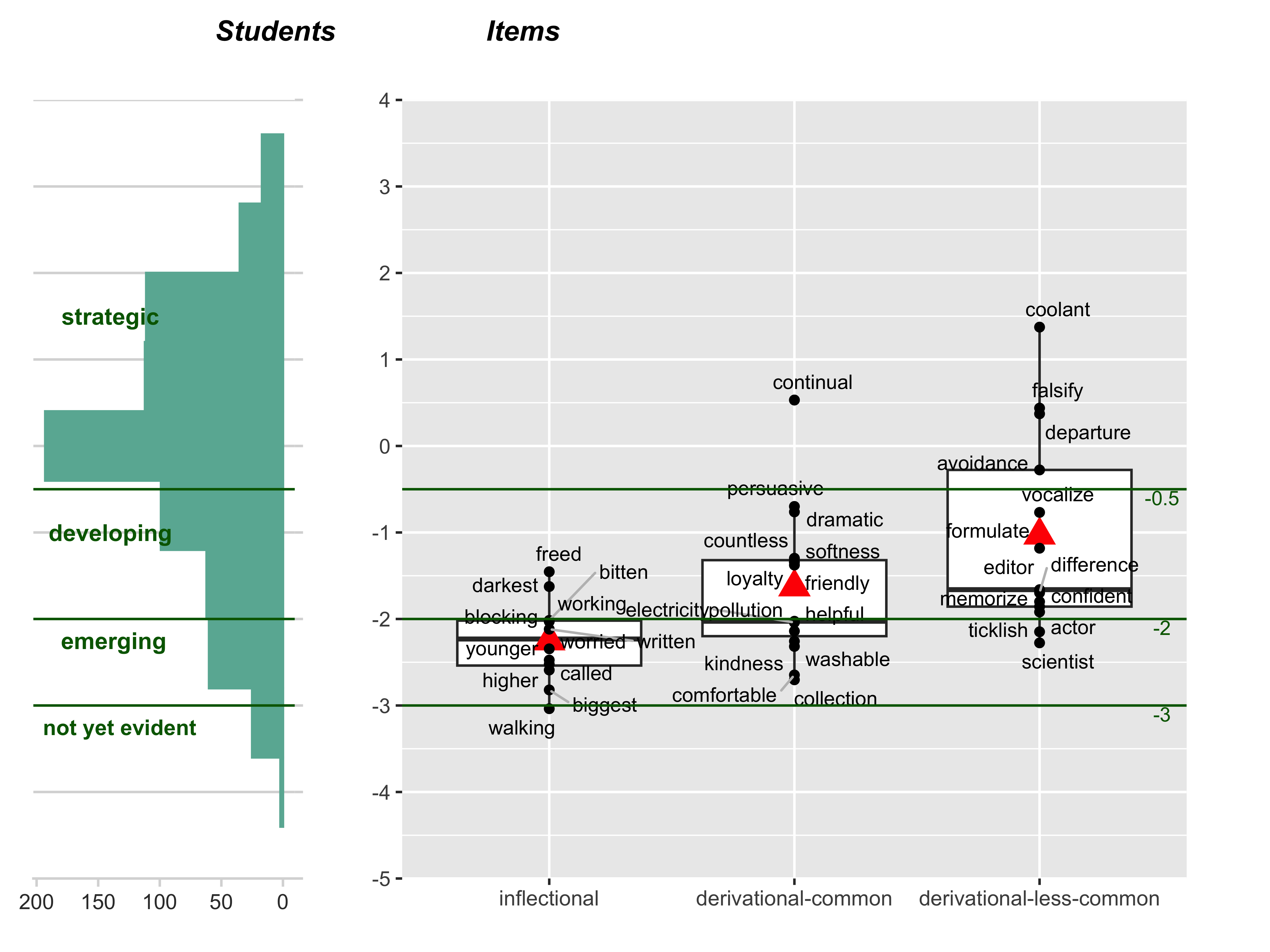
The calibration results from the Rasch model in the form of the Wright map are shown in Figure 13.2. The left-hand side shows a distribution of the ability estimates for the 717 students in the calibration sample, with less proficient students located at the bottom and more proficient students at the top. The estimated ability ranged from -4.67 to 3.48 logits with a mean of -0.03 and a standard deviation of 1.47.
The right-hand side shows the estimated difficulty for the 40 morphology items, indicated by black dots labeled with target words (the correct answers). These items are grouped by three types that align with waypoints 1 through 3 in the construct map: inflectional-common, derivational-common, and derivational-uncommon. Items towards the bottom of the map are easier to answer correctly, while those towards the top are more difficult.
The estimated item difficulty ranged from -3.04 (walking, an inflectional shift item) to 1.37 logits (coolant, a derivational shift item with less-common suffix), with a mean of -1.62 and standard deviation of 0.99. The items cover the ability distribution reasonably well. Additional items will be added to the upper and lower ends to capture the full range of student ability more comprehensively.
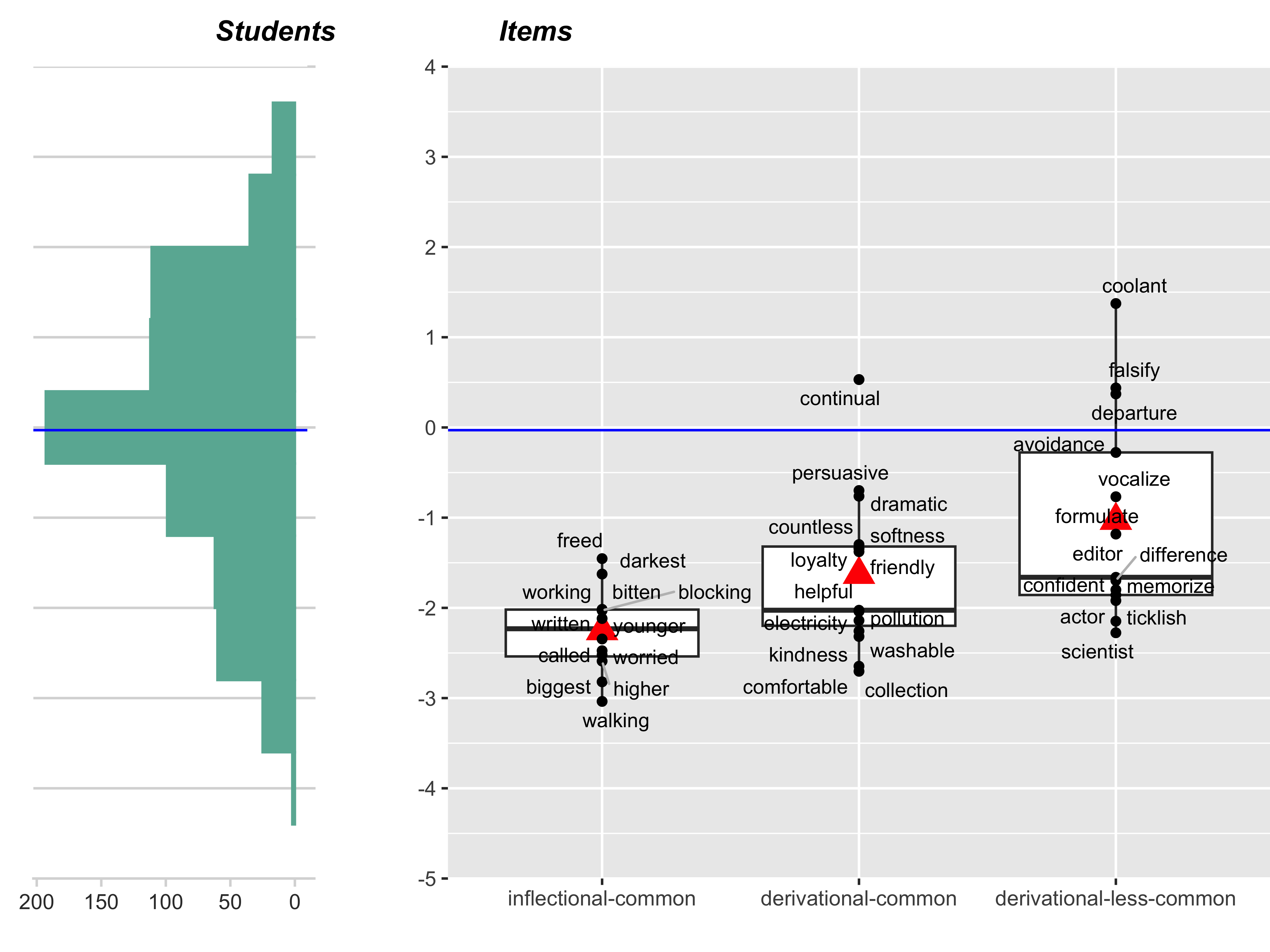
Red triangles on the Wright map show the mean item difficulties of the three item types. An upward trend of these triangles provides support for the hypothesized structure of the construct: on average, items requiring a derivational shift with a relatively common suffix are more challenging than those requiring an inflectional shift, and items requiring a derivational shift with a less common suffix are the most difficult. However, there are some overlaps in item location across the three item types, indicating that item difficulty may also be influenced by factors other than the primary item type.
To illustrate the practical interpretation of these results, a student with the sample average ability (-0.03 logits, shown by the blue horizontal line) has about a 56% chance of correctly selecting avoidance in a derivational-shift item with a less common suffix (this item is 0.28 logits lower than the student with the average ability). The same student has an 81% chance of correctly selecting freed, the most difficult inflectional-shift item in our item sample (this item is 1.45 logits below the average student).
13.3.2 Additional Factors Influencing Item Difficulty
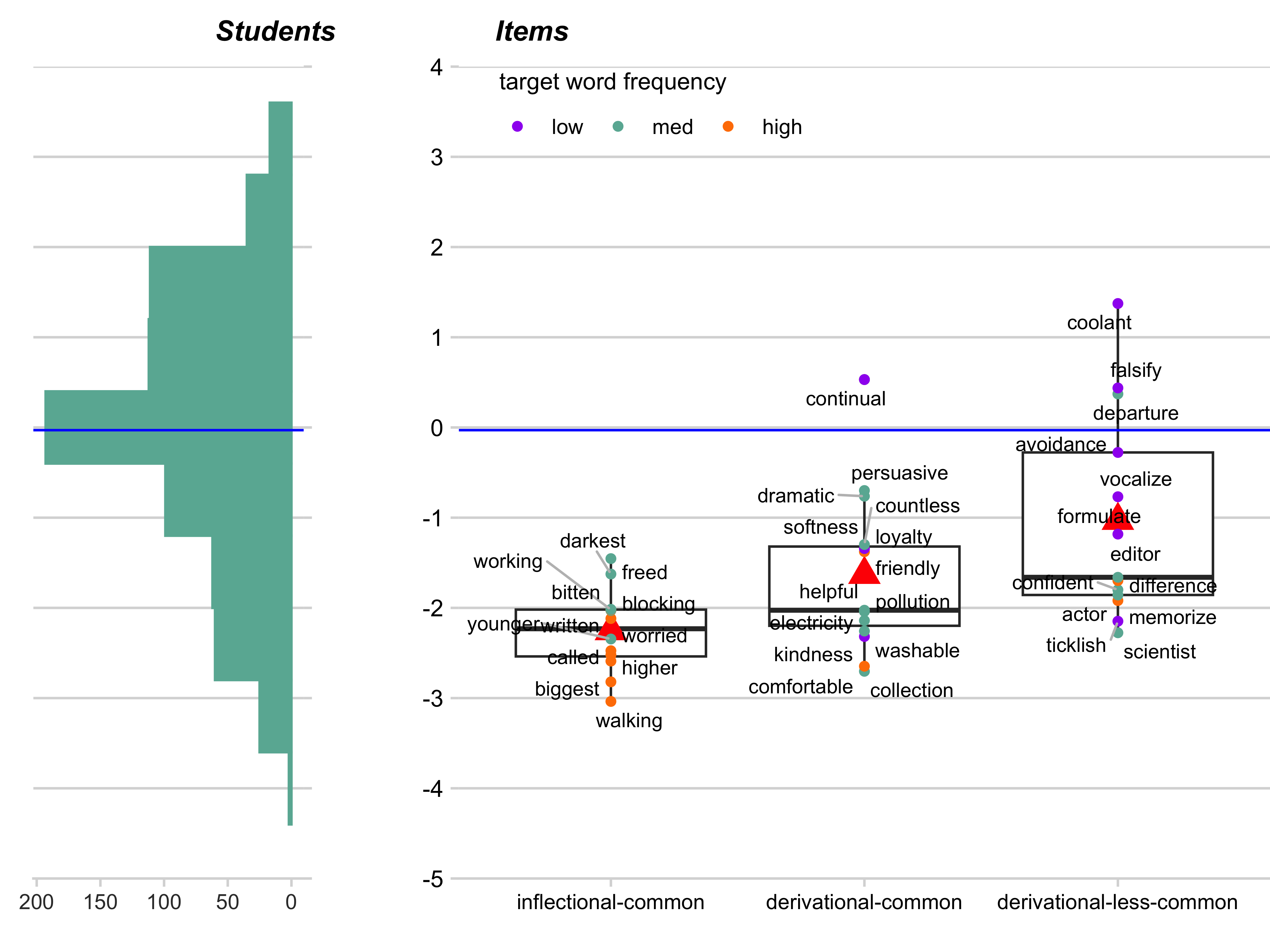
Of the several item- and word-features we examined, two yielded distinctive patterns that help explain variations in item difficulty beyond the primary theoretical structure. First, the number of derivational distractors given in the answer choices (how many of the four answer options contained derivational suffixes, including the target word if it was derivational) systematically affected difficulty. Second, the frequency of target words—a measure that could capture students’ likelihood of exposure to the words (i.e., students are more likely to have encountered more frequent words than less frequent words)— also influenced item difficulty. For target word frequency, we used the log10 of the number of times a particular word appears per million words in the SUBTLEXus corpus— a corpus of words from American English subtitles that is presumed to reflect the general American English usage (Brysbaert and New 2009).
Number of Derivational Distractors Across the three item types, items with 2 derivational distractors are consistently more difficult than those with none or just one derivational distractor, as shown in Figure 13.3.
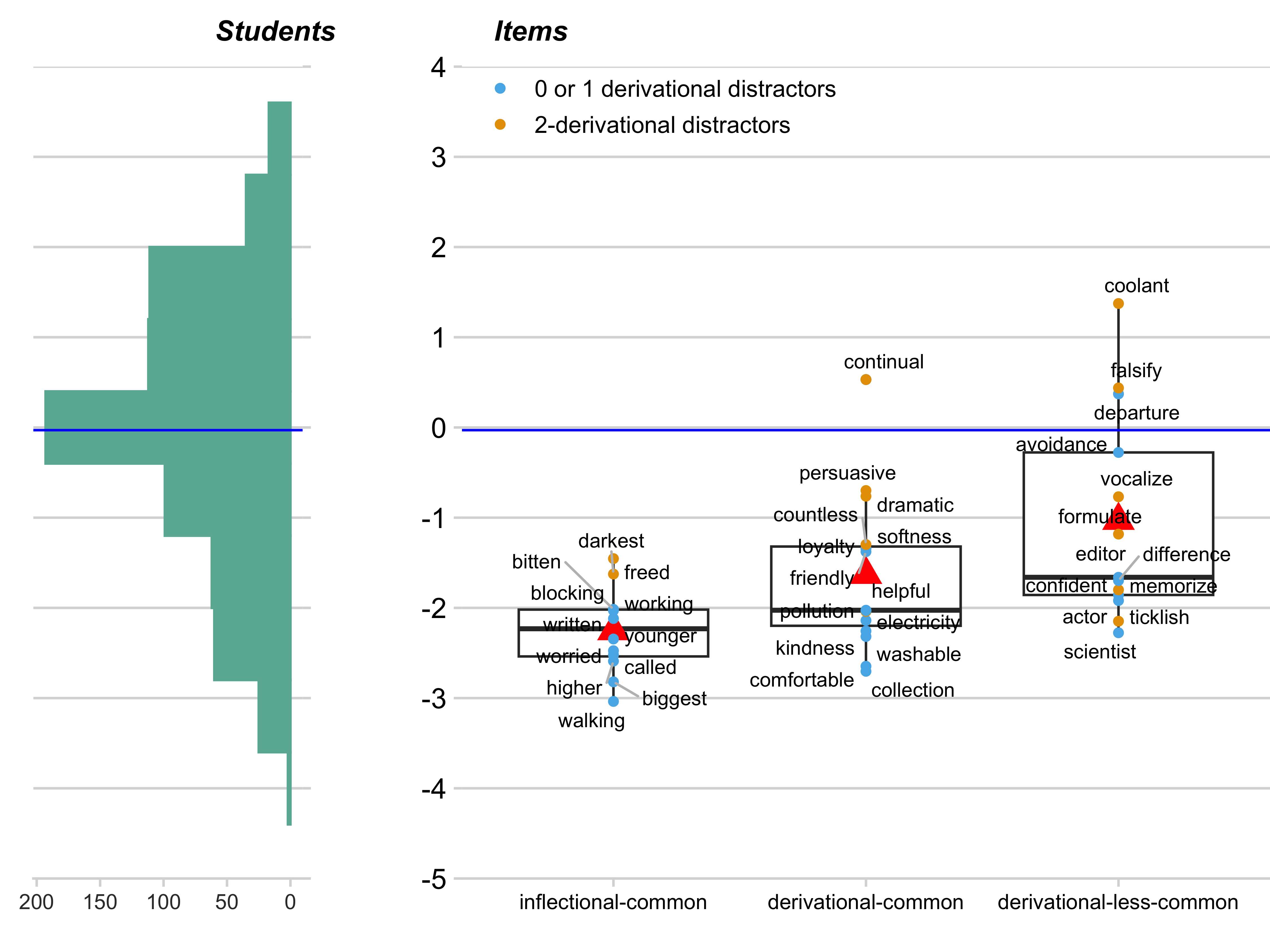
For example, the item ‘The children were (playing) in the park,’ with distractors play/played/player, has only one derivational distractor (player) and is easier than the item, “Wolves show (loyalty) to their pack” with distractors loyal/loyally/loyalist, which contains two derivational distractors (loyally, loyalist). This pattern suggests that the number of derivational distractors functions as a lever for item difficulty, with students possessing deeper morphological knowledge being more likely to handle this challenge and arrive at the correct answer because they are less likely to be confused by such distractors.
Target Word Frequency Similarly, Figure 13.4 shows that low-frequency words (to which students likely have less exposure) tend to appear at higher difficulty locations, making them more challenging. They are followed by medium-frequency words within the two derivational-shift item categories. Within the inflectional shift item category, high-frequency words are mostly concentrated at lower difficulty levels while medium-frequency words appear at higher difficulty levels.
13.4 Cut-Scores & Refined Construct Map
Based on examining the WrightMap, the empirical data largely confirmed our initial theoretical structure while revealing additional nuances in students’ morphological knowledge. While type of morphological shift (inflectional vs. derivational) and suffix frequency (common vs. less common) did create a general progression of difficulty as hypothesized, the additional factors of derivational distractor quantity and target word frequency emerged as significant influences on item difficulty. Items with multiple derivational distractors proved more challenging because students must analyze and reject several morphologically complex alternatives, each requiring consideration of different derivational patterns and their semantic and/or syntactic appropriateness within the sentence context. This finding suggests that students with stronger morphological knowledge are better able to efficiently process and dismiss incorrect morphological forms, while students with weaker morphological knowledge may be more susceptible to confusion when multiple plausible-seeming derivational options are present.
Based on these findings, we set the cut scores as shown in Figure 13.5 to create empirically-based four proficiency bands: strategic, developing, emerging, and not yet evident.
Accordingly, the construct map has been updated, as in Table 13.3. The refined descriptions for the waypoints more precisely reflect the empirical patterns observed in student responses, especially the item-features that drive difficulty, while still aligning with the theoretical progression from emergent to strategic morphological knowledge. This refinement exemplifies the iterative nature of construct mapping within the BEAR Assessment System framework (Wilson 2023), where theoretical constructs are continually validated and refined through empirical evidence to enhance measurement precision and instructional utility.
| Application of Morphological Knowledge | Description |
|---|---|
| Strategic (above -0.50 logits) | Demonstrates a full range of ability for morphological shifts, including derivational shifts in a challenging context (e.g., when the target word is lower in frequency and 2 derivational distractors are present). |
| Developing (-0.50 ~ -2 logits) | Demonstrates some range of ability for morphological shifts even when target words are mid-range of frequency and attractive derivational distractors are present. |
| Emerging (-1.99 ~ -3 logits) | Demonstrates some success with morphological shifts, especially with inflectional shifts in a simple context (when the target ward is high frequency and only 1 or no derivational distractor is presented). |
| Not Yet Evident (below -3 logits) | Does not yet demonstrate the application of morphological knowledge |
13.4.1 Dimensionality
We investigated whether items requiring inflectional shifts and those requiring derivational shifts should be treated as separate dimensions. A multidimensional Rasch calibration (Adams, Wilson, and Wang 1997; Briggs and Wilson 2003) with ConQuest5 found a correlation of .95 between the two latent dimensions: derivational and inflectional items. This correlation is corrected for any attenuation caused by measurement error. The high correlation provides strong evidence that the ROAR-Morphology items measure the same underlying construct rather than two separate dimensions, suggesting these aspects represent a common underlying construct rather than functionally distinct abilities.