| Grade | N |
|---|---|
| 1 | 521 |
| 2 | 596 |
| 3 | 566 |
| 4 | 543 |
| 5 | 589 |
| 6 | 609 |
| 7 | 519 |
| 8 | 425 |
| 9 | 416 |
| 10 | 425 |
| 11 | 399 |
13 Spanish Single Word Reading (ROAR-Palabra)
ROAR-Palabra uses a lexical decision task to measure single word reading ability in Spanish. To our knowledge, the use of lexical decision tasks as a proxy of single word reading ability in Spanish has not been investigated before and we are the first to propose such a task for the purpose of a multinglingual reading screener. We developed this task in response to the need for screening instruments in languages other than English (also see Chapter 12). While additional languages are to follow, we began developing versions of our subtests in Spanish, because it is the most widely spoken language other than English in the United States (and California and New York City specifically). ROAR-Palabra is still under active development and we report on the current fixed-length (62 items) version of the task (i.e., a non-computer-adaptive). For the rationale behind using lexical decision tasks to approximate word reading in general, refer to Chapter 5. For a description of the structure of the task, see Section 5.1, particularly Figure 5.1.
Unlike English, Spanish is a highly phonologically transparent language, meaning that there is a close correspondence between spelling and pronunciation. This transparency requires careful selection of non-words, as they must adhere to Spanish phonotactic rules to avoid creating stimuli that are easily identifiable as non-words based solely on their orthographic structure. Additionally, Spanish morphology is more complex than English, with a rich system of verb conjugations and gendered noun-adjective agreements. Therefore, attention must be given to the morphological structure of the stimuli to ensure that the task captures genuine lexical decision processes rather than responses driven by morphological cues.
13.1 Task Development
ROAR-Palabra is explicitly not a translation of the ROAR-Word— simple translations usually fail to produce equivalent versions of a test (Solano-Flores, Backhoff, and Contreras-Niño 2009). In contrast to many other non-English measures, we started the development process from a Spanish perspective: we created an initial list of stimuli by prompting ChatGPT to produce a list of frequent Spanish words, known to pre- and middle-schoolers across the Americas and occurring in all the varieties of Spanish spoken there. We then then used the Wuggy algorithm (Keuleers and Brysbaert 2010) to create matching, word-like pseudowords—stimuli conforming to Spanish orthographic rules and matching the real word list in terms of word length, letter-transition frequencies, and orthographic neighborhood size. Candidate items were then inspected by experts in reading development who speak various regional varieties of Spanish. The goal was to create an assessment that would be equitable across the wide variety of Spanish language varieties that are spoken in the United States. Spanish speakers from Colombia, Ecuador, Mexico, and Spain independently reviewed both the real and pseudowords. Items flagged as problematic due to, for example, low frequency of occurrence or inappropriate slang meanings in any one of the varieties of Spanish were removed.
This process resulted in an initial item bank with 378 item pairs (that is 189 real words and 189 matched pseudowords). To keep administration time reasonable, we randomly selected 70 core items (35 real and 35 pseudowords), which form the basis of the current version. Every test-taker responded to these core items, as well as 30 additional items (15 real and 15 pseudowords) randomly selected from the broader item pool. In future versions, these additional items will be calibrated, too, so that the task can be made computer-adaptive.
13.1.1 California and Colombia Calibration Sub-samples
To account for regional variations in the Spanish language, as well as for the different linguistic profiles of monolingual and multilingual speakers of Spanish (see Chapter 12), we developed the ROAR-Palabra using data from 6,034 K-11th grade students from a First-language Spanish-speaking sample in Colombia, as well as 426 K-2 students from a a multilingual sample from a school district in California. This allowed us to ensure that the task is appropriate for use in Spanish-speaking populations with different linguistic and cultural backgrounds. Table 13.1 shows the grade-level distribution of the Colombian sub-sample. Table 13.2 shows the demographic characteristics of the California sub-sample.
| Characteristic | Kindergarten N = 5 | Grade 1 N = 201 | Grade 2 N = 219 |
|---|---|---|---|
| Female | 3 (60%) | 96 (48%) | 81 (38%) |
| Unknown | 0 | 3 | 4 |
| Free/Reduced-price Lunch Eligibility | 3 (60%) | 140 (70%) | 155 (71%) |
| Special Educational Needs | 1 (20%) | 21 (11%) | 26 (12%) |
| Unknown | 0 | 3 | 3 |
| English Proficiency Status | |||
| EL | 2 (40%) | 121 (61%) | 145 (67%) |
| EO | 2 (40%) | 52 (26%) | 48 (22%) |
| IFEP | 1 (20%) | 14 (7.1%) | 12 (5.6%) |
| RFEP | 0 (0%) | 11 (5.6%) | 10 (4.6%) |
| TBD | 0 (0%) | 0 (0%) | 1 (0.5%) |
| Unknown | 0 | 3 | 3 |
| Primary Language | |||
| English | 2 (40%) | 74 (41%) | 92 (45%) |
| Spanish | 3 (60%) | 107 (59%) | 111 (55%) |
| Unknown | 0 | 20 | 16 |
| Race | |||
| Asian | 0 (0%) | 3 (1.5%) | 0 (0%) |
| Black or African American | 0 (0%) | 3 (1.5%) | 0 (0%) |
| Filipino | 0 (0%) | 1 (0.5%) | 0 (0%) |
| Hawaiian or Other Pacific Islander | 0 (0%) | 1 (0.5%) | 0 (0%) |
| Hispanic | 3 (60%) | 178 (90%) | 194 (100%) |
| White | 2 (40%) | 12 (6.1%) | 0 (0%) |
| Unknown | 0 | 3 | 25 |
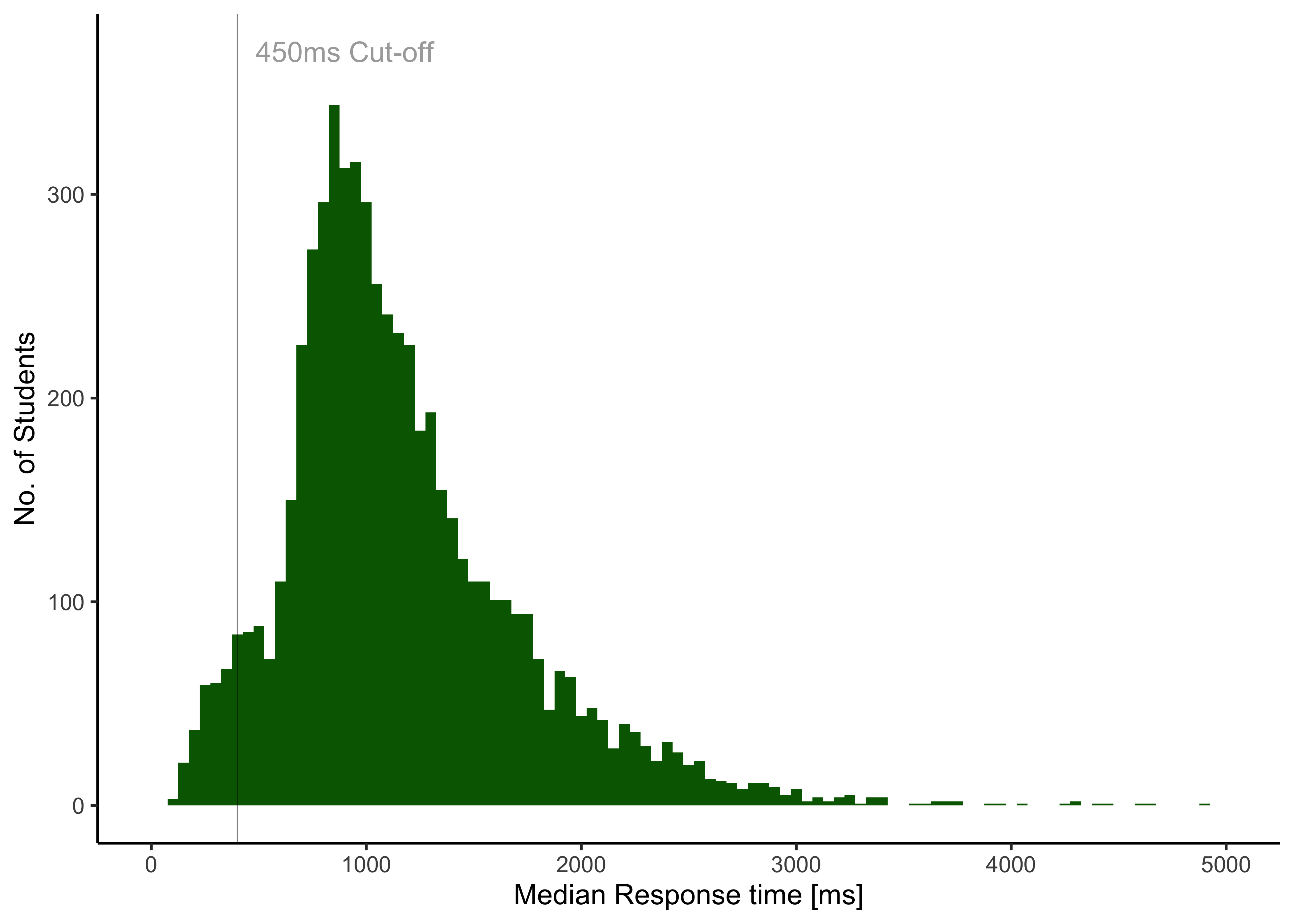
13.1.2 Response Time
Figure 13.1 shows the distribution of students’ median response times on the ROAR-Palabra. Following the rationale outlined in Chapter 17), participants with a median response time <450ms were excluded from further analyses. This results in 374 of 6028 students (6.2 %) being excluded from further analyses due to guessing or other unreliable testing behaviors.
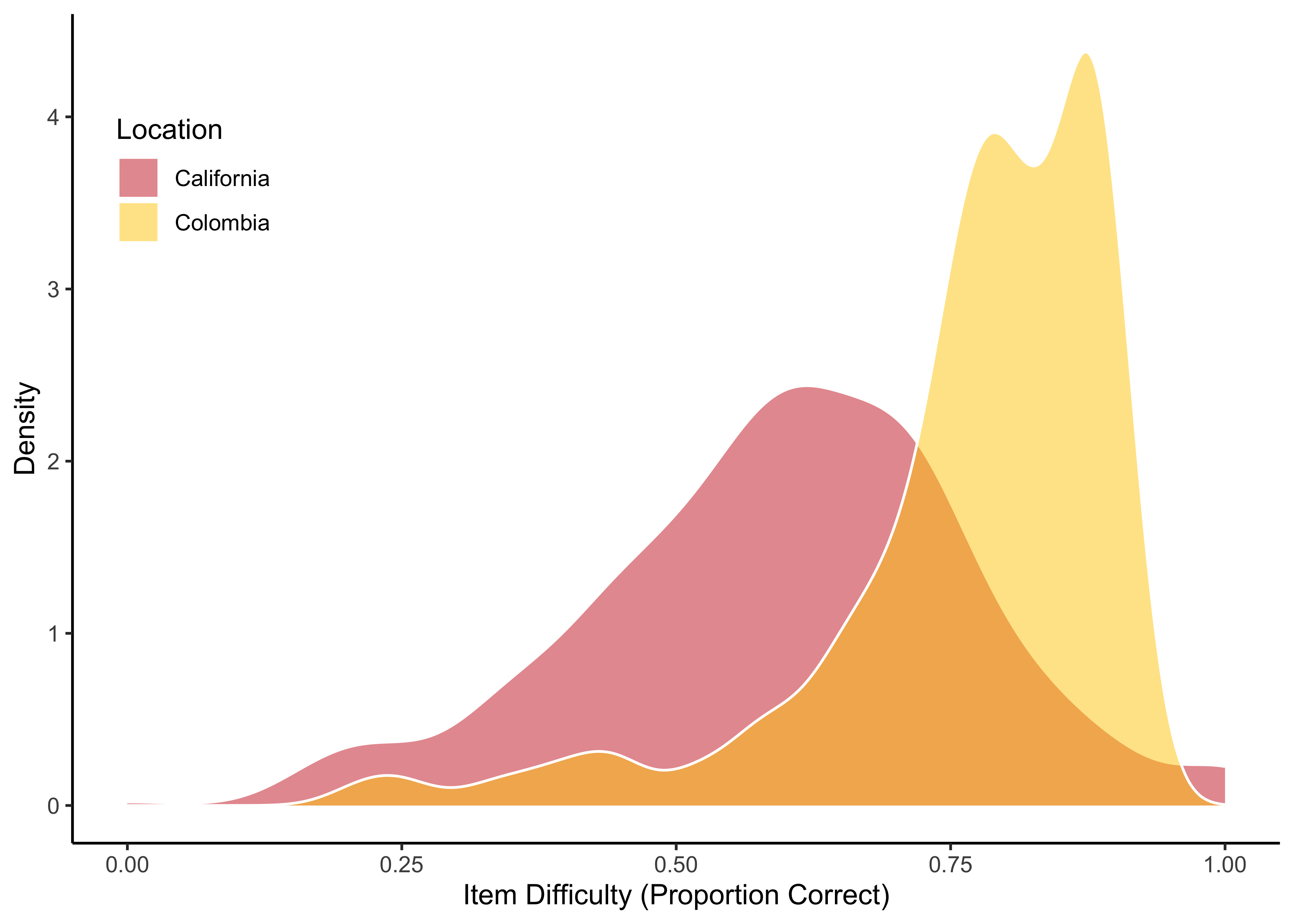
13.1.3 Item Properties
Overall, items tended to be easier for students in Colombia; this is expected, as these students are First-language Spanish speakers instructed in their first language, while the Californian sub-sample is more linguistically diverse in terms of their Spanish abilities and their instructional programs. Also, the Colombian sub-sample drawn on here consists of students from grades 1-11. While this disallows for a meaningful direct comparison of ROAR-Palabra scores between Californian and Colombian students, ROAR-Palabra can, nonetheless, function as a useful task to tell apart higher from lower performing students within any of these populations.
13.2 ROAR-Palabra Norms for Monolingual Spanish Speakers
As described in Section 12.3, an initial norming study was completed in a primarily monolingual Spanish speaking sample in Colombia. ROAR-Palabra was delivered to all students above 1st grade in Colombia. We then ran another group of bilingual students in California in grades 1 and 2. Figure 30.5 displays the norms by grades. Scores for a representative sample of multilingual learners in California are shown relative to the monolingual norms.
References
Keuleers, Emmanuel, and Marc Brysbaert. 2010. “Wuggy: A Multilingual Pseudoword Generator.” Behavior Research Methods 42 (3): 627–33. https://doi.org/10.3758/brm.42.3.627.
Solano-Flores, Guillermo, Eduardo Backhoff, and Luis Ángel Contreras-Niño. 2009. “Theory of Test Translation Error.” International Journal of Testing 9 (2): 78–91. https://doi.org/10.1080/15305050902880835.