Reliability of calibration sample
A Rasch plus guessing model was fit to the ROAR-Letter calibration sample (see Table 8.1 and Table 8.2). All ROAR-Letter items fit the model well (see Chapter 4 for fit criteria). Calibration data were obtained from 5365 students who took ROAR-Letter. Two versions of ROAR-Letter were administered: 1668 students took the full, 88-item version with no time limit and 3697 students took a shorter version consisting of 10 letter names and up to 36 letter-sound items with a 5-minute time limit. Based on this IRT model, overall empirical reliability for ROAR-Letter was 0.87 (95% CI: 0.86 to 0.87).
Reliability of computer-adaptive ROAR-Letter
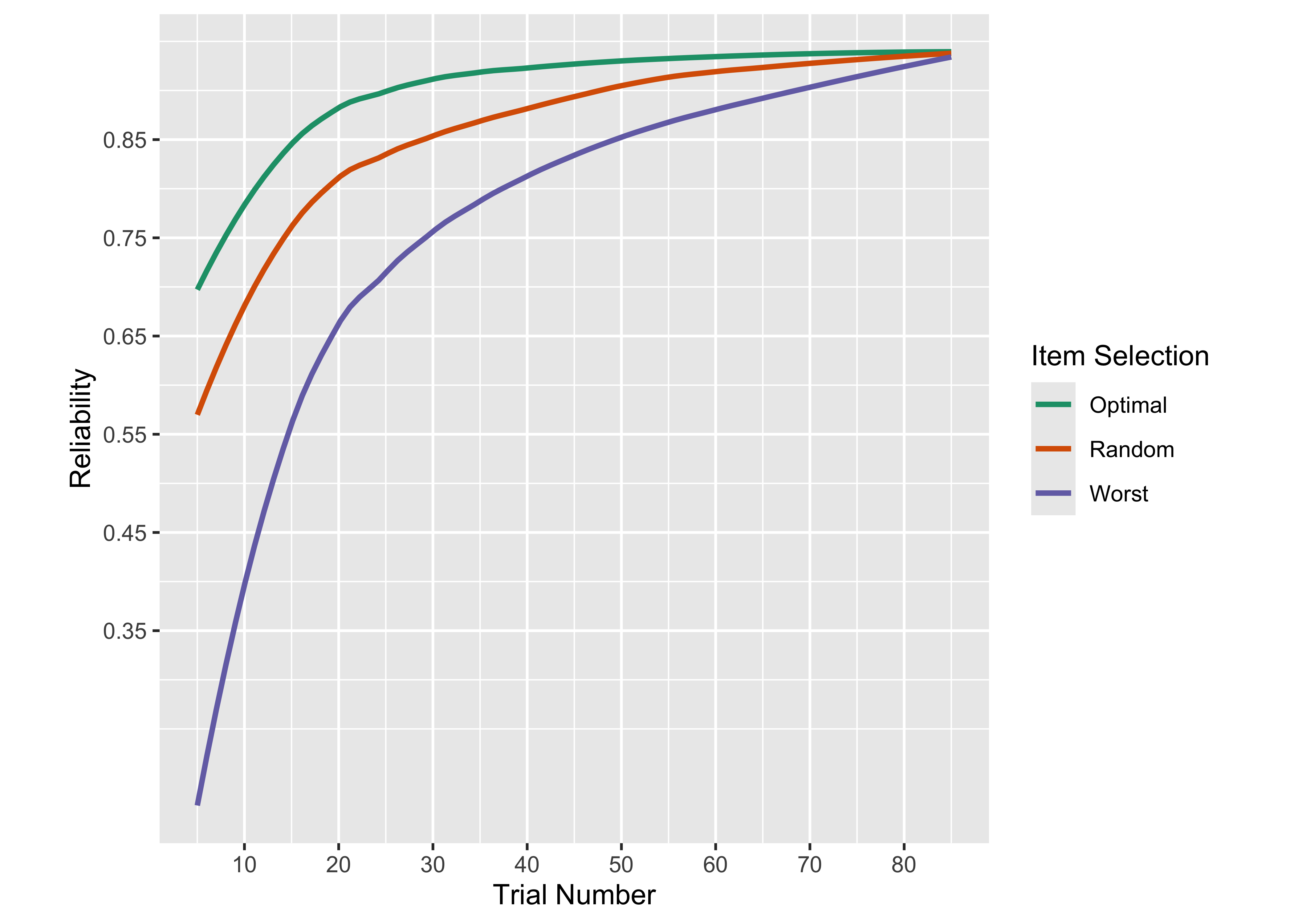
A computer-adaptive version of ROAR-Letter is more efficient than a fixed-length form while still providing reliable scores; however, it is important to consider the manner in which the items are selected. We ran a CAT simulation as described in (Ma et al. 2023) to determine the item selection criteria that would maximize reliability in the fewest number of trials (Figure 20.1). After selecting 25 trials as the most efficient number, we simulated a 25-trial computer adaptive test using participant responses.
Reliability (\(\rho_{xx^\prime}\)) is computed based on the estimated variance of \(\hat{\theta}\) relative to the estimated standard error (\(\widehat{SE}(\hat{\theta})^2\)) using Equation 26.1.
Students who answered every administered item correctly were excluded from the reliability calculation, since their theta and SE are determined by the prior rather than the data. After this filter, 4078 of 5178 calibration students remained (1100 excluded). Based on the 25-item optimal CAT, overall empirical reliability for ROAR-Letter was 0.86 (95% CI: 0.85 to 0.86).
Table 20.1 reports marginal reliability by grade, based on a 25-item simulation of an optimal item selection algorithm using participant data. To ensure that ROAR-Letter is fair and equitable for different demographic groups, we also report reliability by gender (Table 20.2), eligibility for free and reduced price lunch (Table 20.3), English learner status based on state of California designations (Table 20.4), primary language spoken (Table 20.5), special education (Table 20.6), ethnicity (Table 20.7), and race (Table 20.8).
References
Ma, Wanjing A, Adam Richie-Halford, Klint Burkhardt Amy and Kanopka, Clementine Chou, and Jason D Domingue Benjamin and Yeatman. 2023. “ROAR-CAT: Rapid Online Assessment of Reading Ability with Computerized Adaptive Testing.”