22 Reliability and Validity of Dyslexia Prediction and Subtyping
Many dyslexia screening initiatives require the use of specific measures such as Rapid Automatized Naming (RAN; see Chapter 11) and measures of visual processing (RVP; see Section 10.2.1). The following sections report the reliability and validity of ROAR measures that were specifically designed for dyslexia prediction and subtyping (see Section 10.2 for more information and a theoretical background on the measures).
22.1 Reliability of ROAR Rapid Automatized Naming (ROAR-RAN)
Overall, ROAR-RAN and the automated scoring algorithm demonstrate exceptional reliability and validity (see Chapter 23). Automated RAN scores strongly correlate with scores generated manually. Further, RAN scores show the expected correlations with other measures within ROAR Foundational Reading Skills Suite, suggesting good concurrent validity of the measure. Future longitudinal work is required to demonstrate the predictive validity of ROAR-RAN.
22.2 Reliability of ROAR Rapid Visual Processing (ROAR-RVP)
22.2.1 Background: Published studies
The rapid visual processing paradigm that was administered to older children between 7-17 years (Ramamurthy, White, and Yeatman 2024) was translated for a younger population and a computer adaptive testing algorithm was implemented see 4 in order to improve reliability and ensure the task spans a broad age range. We translated the task for a younger population by iteratively changing the task and the design while administering it to small groups of kindergarten and first graders within the Multitudes study sample population. This work was done through collaboration between the ROAR team at Stanford University and the Multitudes Team at UCSF. The final versions are tailored to Kindergarten and first grade children but spans through adulthood. Details of the design and validation process are published in Ramamurthy et al. (2024).
22.2.2 Data informed design changes to achieve high reliability in young children
For the RVP measure item difficulty depends on a variety of task parameters. There are two important task parameters that have the potential to influence performance: 1) encoding time and 2) string length.
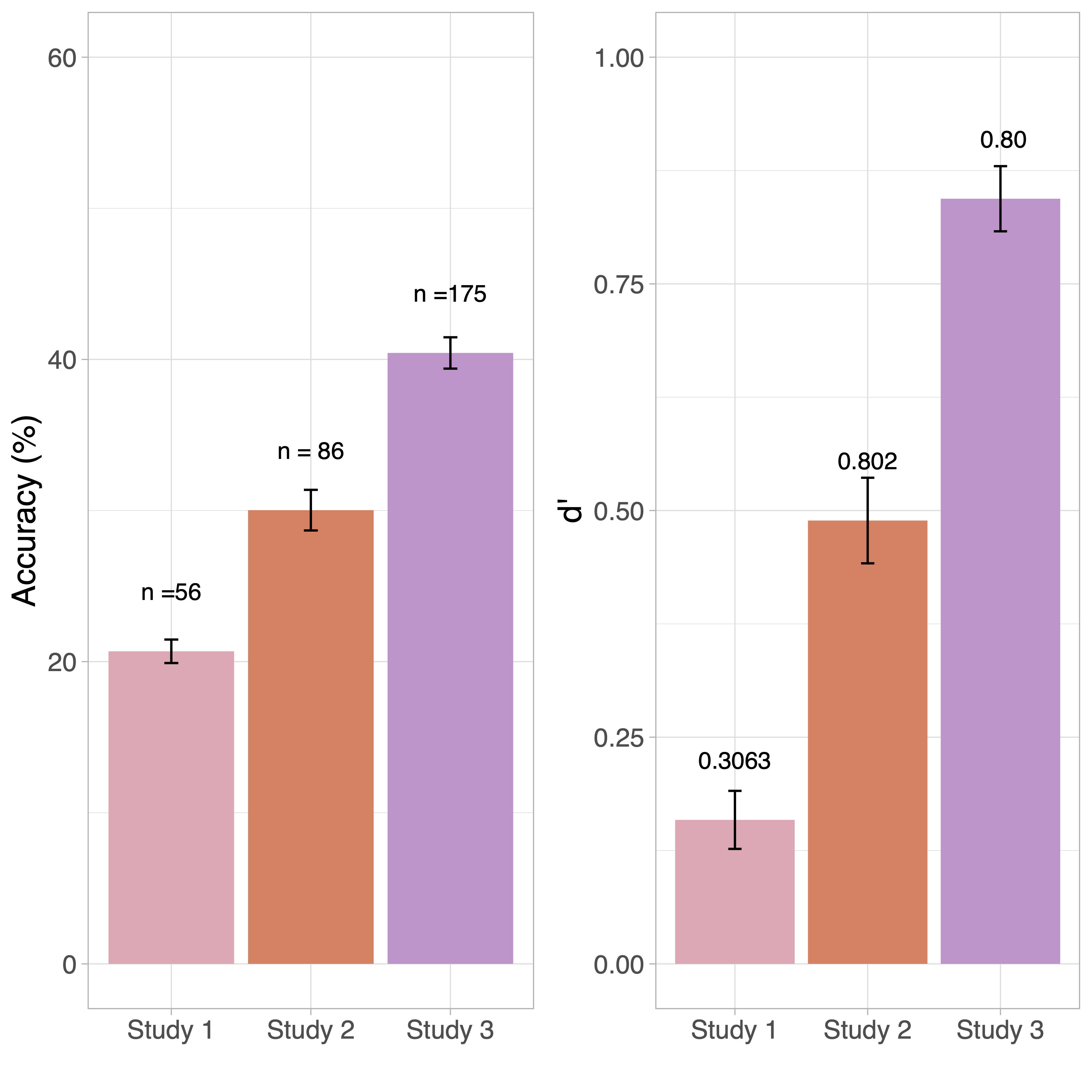
22.2.2.1 Study 1 (N = 56)
We first administered the task with similar parameters as were used in our previous study of older children and adults (Ramamurthy, White, and Yeatman 2024) (encoding time of 120ms and string length of 6 letters). We observed that K/1 children’s task performance was significantly lower with an encoding time of 120ms (16.813% +/- 7.654) with very low reliability (Spearman Brown corrected split half reliability: 0.075) compared to the older cross-sectional population reported in our previous work (37.148% +/- 1.191; reliability: 0.8). However, performance increased with an encoding time of 240 (21.125%+/- 8.371) and 480 ms (24.107% +/- 9.851; d’: 0.269). Notably, even at 480ms many participants still performed at chance and reliability was still low (Spearman Brown corrected split half reliability was 0.306).
22.2.2.2 Study 2 (N = 86)
We tested how performance changes in trials with four elements (2 on either side of fixation) and six elements (3 on either side of fixation) with encoding times of 240 ms and 480 ms. We observed that there was an overall improvement in task performance in Study 2 [Mean accuracy: 30.025 +/- 1.344] compared to the overall task performance from Study 1 [Mean accuracy: 20.685 +/-0.777; Mean d’: 0.159+/-0.032 ].
22.2.2.3 Study 3 (N= 175)
In the next iteration, we added a 2-element string in addition to 4- and 6- element strings. We further reduced redundancy by removing an encoding time of 480 ms that did not increase accuracy. An encoding period 240 ms ensures that encoding occurs without making a saccadic eye movement (Li, Hanning, and Carrasco 2021). Overall task performance increased significantly compared to Studies 1 and 2. Performance in Study 3 (40.429% +/- 1.0368) is comparable to the overall performance reported in a previous study with cross-sectional data (n=185) (Ramamurthy, White, and Yeatman 2024), where overall task performance for 6 to 17 yr olds in the MEP task with an encoding time of 120ms and a string length of 6 elements was 37.148% +/- 1.191. Overall task reliability was comparable between Study 3 (r = 0.8) and Study 2 (r = 0.802) see Figure Figure 22.1 below.
22.2.2.4 IRT to model item difficulty levels and to optimize task parameters
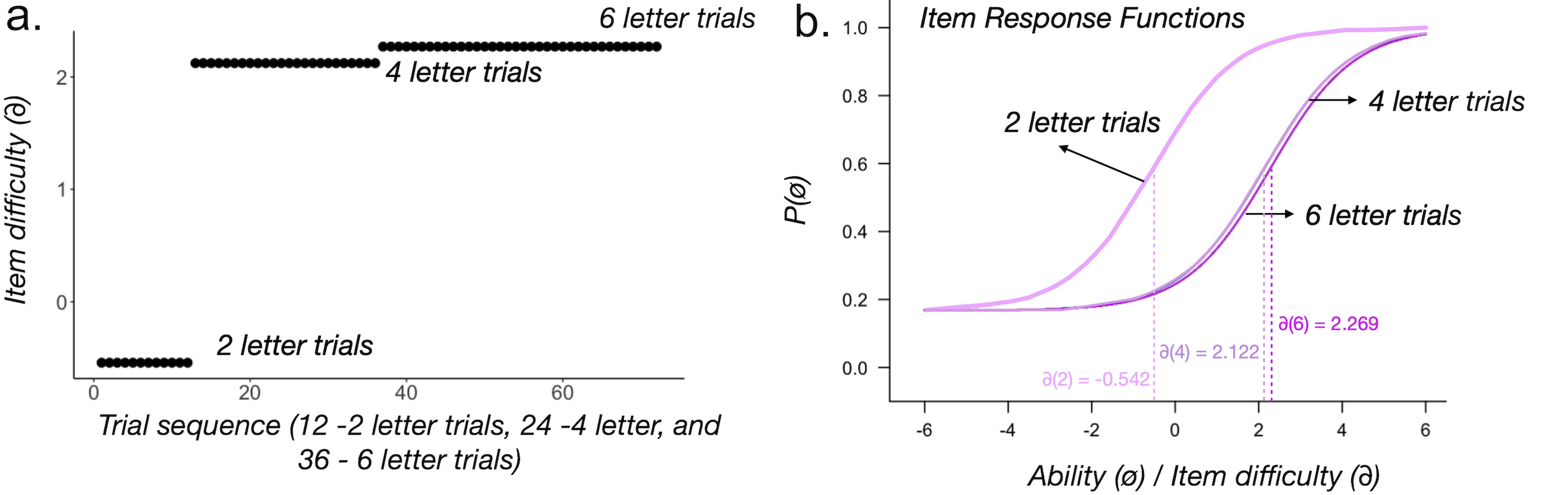
Data from Study 3 (N = 175) was used to calibrate an Item Response Theory (IRT) model. Trials with different string lengths were blocked (twelve 2-letter trials, twenty four 4-letter trials and thirty six 6-letter trials) respectively. The goal of IRT is to place item difficulty (blocks of different string lengths) on an interval scale. The Rasch model (1 parameter logistic with a guess rate fixed at 0.167) was fit to the response data for the 3 item types (constraining difficulty for repeated trials with the same string lengths) for all 175 participants using the MIRT package in R (Philip Chalmers 2012). Figure 22.2 shows item difficulty for each block (a) and item response functions for all three blocks of different string lengths (b).
22.2.2.5 Final Optimized version
As a first step towards reducing redundancy, we can shorten the task by eliminating the thirty six 6-element trials completely and used 2- and 4- element trials with an encoding time to 240ms. Further, for efficient task administration we built a simple transition rule and a termination rule. At the end of the 2-element block if children get 4 or more trials correct (>=4/24) then they transition to the next item difficulty and complete eight 4-letter trials. If children perform at or below chance then the task terminates after twenty four 2-letter trials.
22.2.3 Construct validity: performance on RVP-Letters and RVP-Symbols is highly correlated
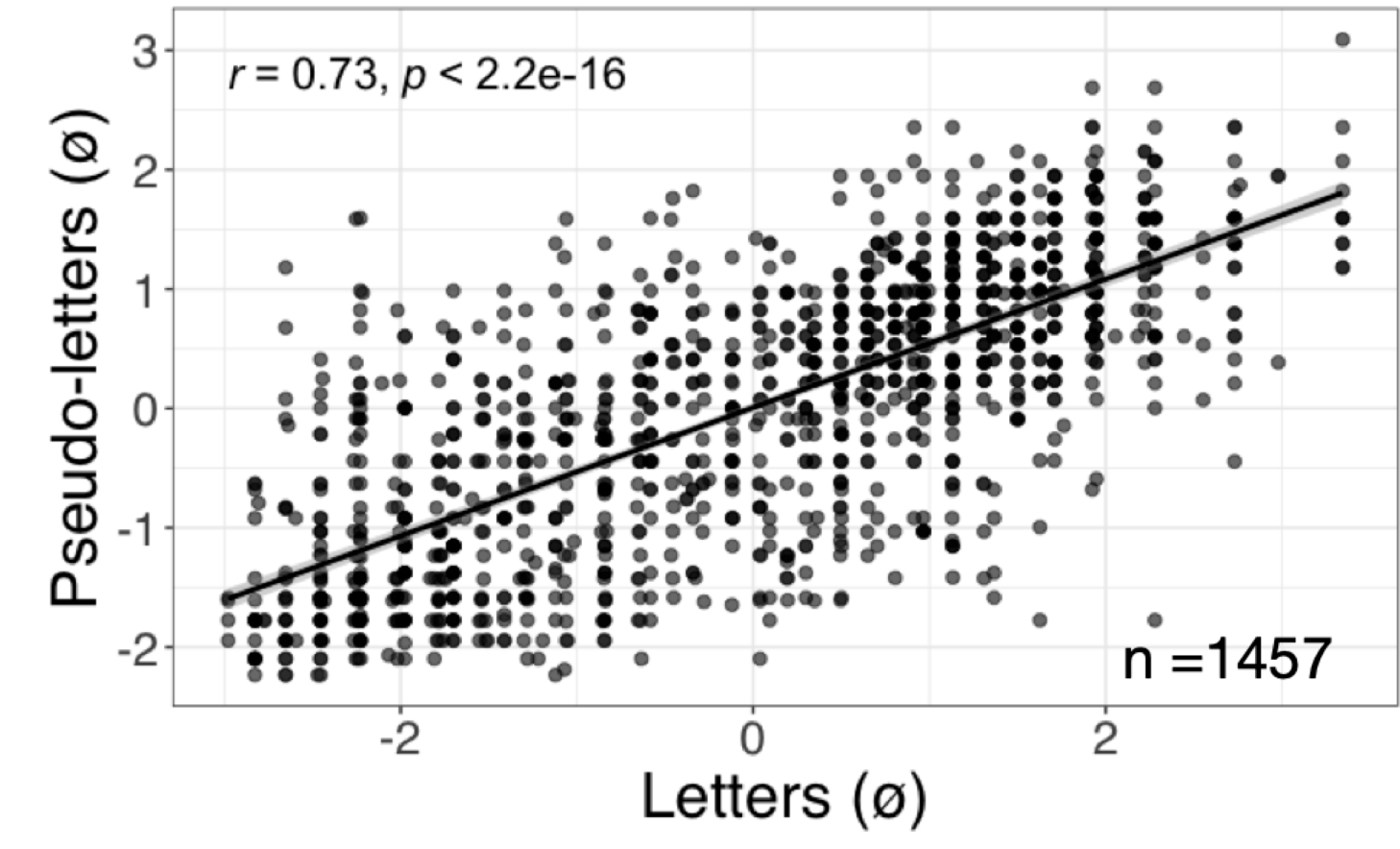
We used the optimized version of the RVP task described above and created two versions 1) letters and 2) symbols (pseudo-letters). These measures were administered to 1457 children in K/1 across the state of California by the UCSF Dyslexia Center as part of an initiative to develop a universal dyslexia screener, Multitudes. As an initial proof-of-concept study we compared ability in the RVPL task and RVPS task and found a high correlation (r = 0.73; dis-attenuated r = 0.9125 given task reliability of 0.80, Figure 22.3). This provides evidence that both RVPL and RVPS reliably tap into the same latent construct.