17 Reliability of ROAR-Word
17.1 Background: Published studies
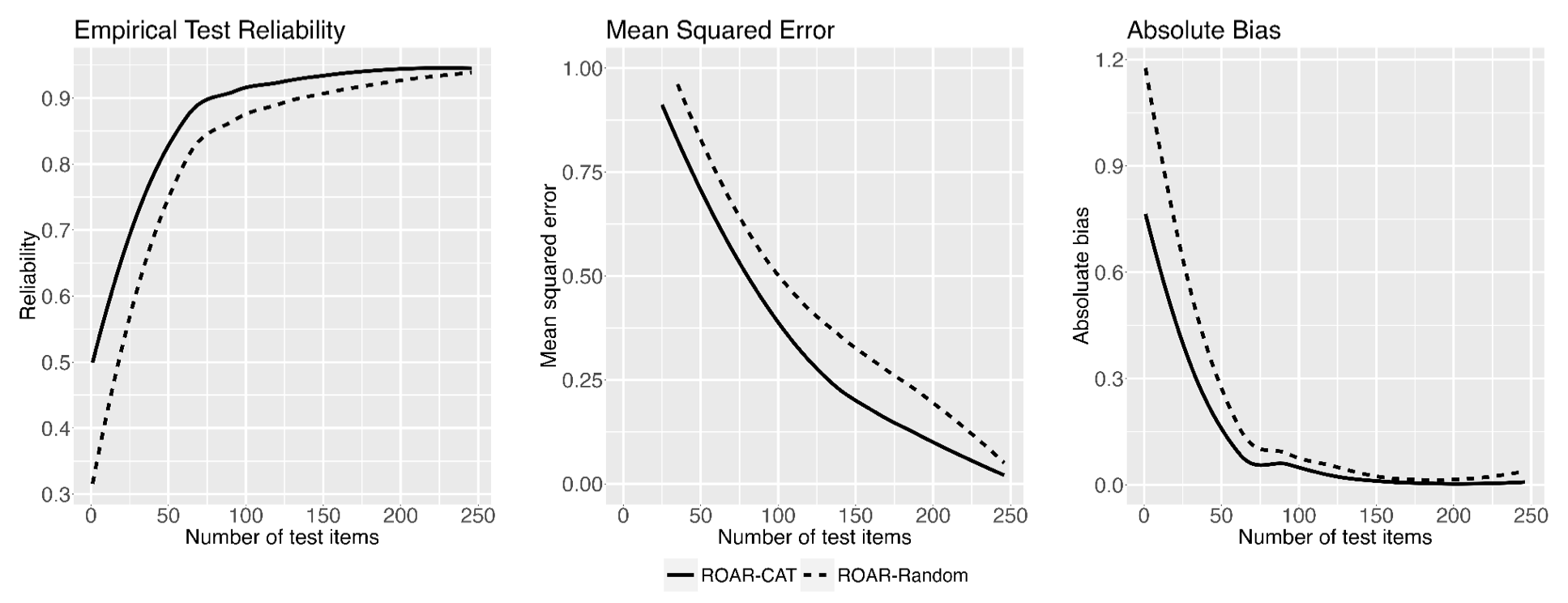
The first published version of ROAR-Word achieved exceptional alternate form reliability (r=0.95) using fixed forms that were equated based on item response theory (Yeatman et al. 2021). To improve efficiency of ROAR-Word, Ma et al. (2023) built the first, open-source, computer adaptive testing (CAT) algorithm in Javascript, and then ran a series of experiments to study how reliability and efficiency of ROAR-Word could be improved with CAT. Figure 17.1 reproduces a figure from Ma et al. (2023) showing an experiment comparing ROAR-CAT to a standard, non-adaptive testing approach. In this experiment, participants were randomly assigned to complete ROAR-Word with the trial order controlled by either a) jsCAT (solid line) versus b) random item sampling (dotted line). ROAR-CAT achieved the same reliability in roughly 40% fewer trials.
This innovation has now been incorporated into all the ROAR measures to create quick and efficient, adaptive assessments that span broad age ranges.
17.2 Criteria for identifying disengaged participants and flagging unreliable scores
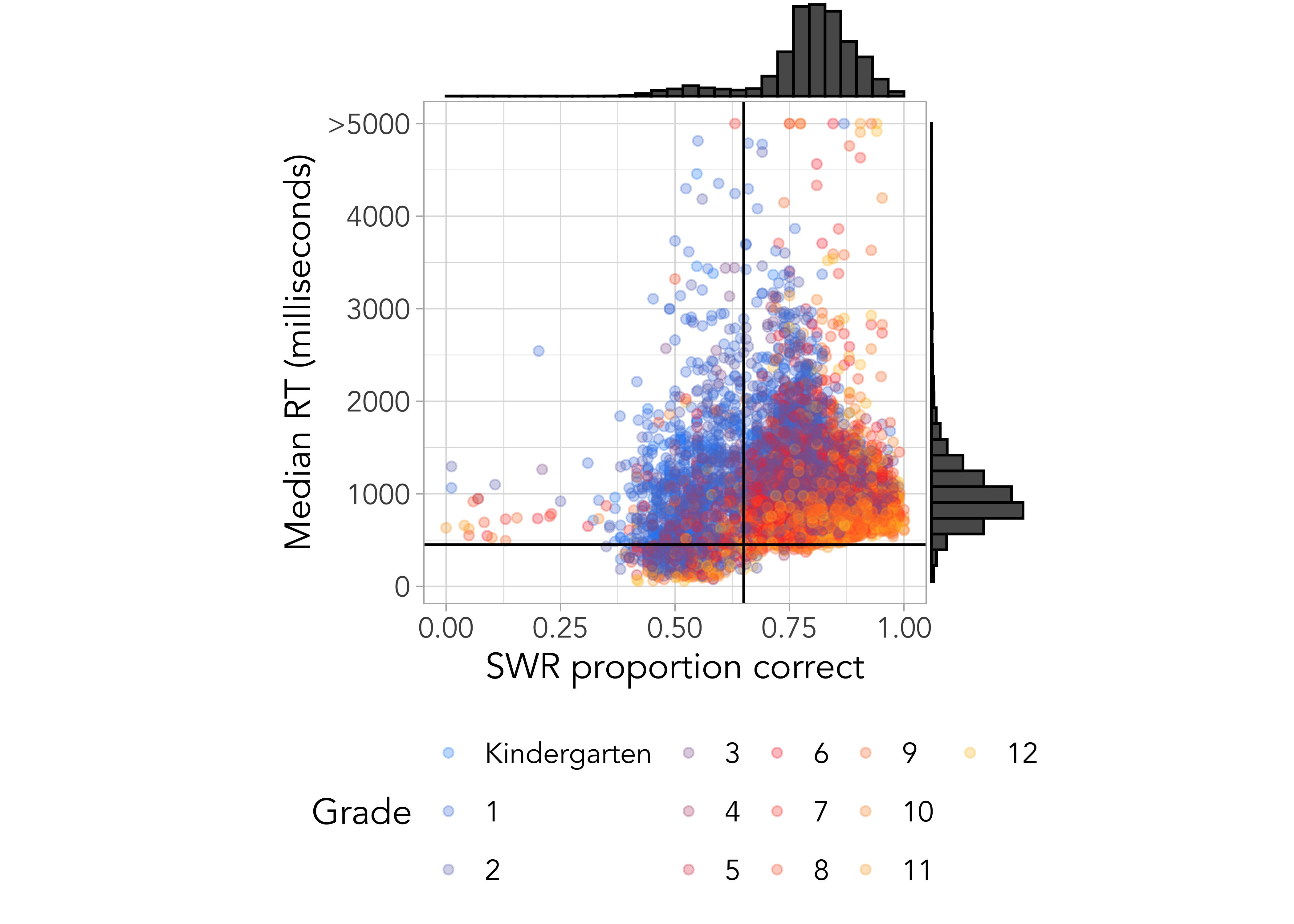
ROAR-Word is designed to be totally automated: instructions and practice trials are narrated by characters, words are read silently, responses are non-verbal, and scoring is done in real time after each response. This makes it child-friendly, eradicates issues related to inter-rater reliability, and makes it possible to efficiently assess a whole school district simultaneously. However, a concern about automated assessments is that without a teacher to individually administer items, monitor, and score responses, some students might disengage and provide data that is not representative of their true ability. One benefit of a lexical decision task is that there is an extensive literature on the expected response time distribution (Balota, Yap, and Cortese 2006; Keuleers, Lacey, and Rastle 2012; Balota et al. 2007). Based on the amount of time it takes signals from the eye to reach the brain, for the visual features to be processed, the word to be recognized, and a motor response to be initiated, extremely fast response times are most likely due to rapid guessing behavior indicative of disengagement from the assessment (Ratcliff, McKoon, and Gomez 2004; Balota, Yap, and Cortese 2006). Our previous publications have validated fast response time as an indicator of participant disengagement (Ma et al. 2023; Yeatman et al. 2021). This effect can be seen in Figure 17.2 which shows a plot of median response time (RT) versus proportion correct for each participant. None of the participants with a median response time less than 450ms (horizontal black line in Figure 17.2) are accurate on ROAR-Word. Since ROAR-Word is run as a computer adaptive test (CAT), All participants should be around 75% correct: item difficulty changes adaptively based on participant responses. Participants that respond very quickly and inaccurately are disengaged and not providing data that is representative of their true ability.
Criteria for flagging unreliable scores
Participants with low accuracy (<65% correct) and a median response time <450ms are flagged in ROAR-Score reports and their data is excluded from analyses. Teachers can choose whether to re-administer ROAR or interpret data cautiously in relation to other data sources and contextual factors.
17.3 Reliability of computer adaptive ROAR-Word
ROAR-Word runs as computer adaptive test based on a Rasch model. The current, default version of ROAR-Word takes about 4 minutes (84 items). More items can be administered for a more precise measure or fewer items can be administered as a quick screener. Table 17.1 reports marginal reliability computed based on data from 23548 students under the IRT model for the standard, 84 item version of ROAR-Word. Reliability (\(\rho_{xx^\prime}\)) is computed based on the estimated variance of \(\hat{\theta}\) relative to the estimated standard error (\(\widehat{SE}(\hat{\theta})^2\)) using Equation 26.1:
\[ \hat{\rho}_{xx^\prime} = \frac{\widehat{VAR}(\hat{\theta})}{\widehat{VAR}(\hat{\theta}) + \widehat{SE}(\hat{\theta})^2}, \tag{17.1}\]
| Grade | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 23548 |
| Kindergarten | 0.84 | 0.81 to 0.86 | 399 |
| 1 | 0.92 | 0.92 to 0.92 | 2046 |
| 2 | 0.93 | 0.93 to 0.93 | 2318 |
| 3 | 0.94 | 0.93 to 0.94 | 1144 |
| 4 | 0.93 | 0.93 to 0.94 | 1389 |
| 5 | 0.93 | 0.92 to 0.93 | 1297 |
| 6 | 0.92 | 0.92 to 0.93 | 1992 |
| 7 | 0.92 | 0.91 to 0.92 | 1934 |
| 8 | 0.92 | 0.91 to 0.93 | 1259 |
| 9 | 0.91 | 0.91 to 0.91 | 4877 |
| 10 | 0.90 | 0.90 to 0.91 | 2170 |
| 11 | 0.90 | 0.89 to 0.91 | 1622 |
| 12 | 0.90 | 0.89 to 0.91 | 1101 |
To ensure that ROAR-Word is a fair and equitable assessment across different demographic groups we also report reliability separately by gender (Table 17.2), eligibility for free and reduced price lunch (Table 17.3), English learner status as designated by the school district (Table 17.4), primary language (Table 17.5), special education (Table 17.6), ethnicity (Table 17.7), and race (Table 17.8)
| Gender | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 16096 |
| Female | 0.94 | 0.94 to 0.94 | 8000 |
| Male | 0.94 | 0.94 to 0.94 | 8096 |
| Free/Reduced Lunch Status | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 2164 |
| Free/Reduced | 0.94 | 0.94 to 0.95 | 379 |
| Paid | 0.93 | 0.93 to 0.94 | 1785 |
| English Learner Status | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 2891 |
| English Learner | 0.93 | 0.92 to 0.93 | 379 |
| English Only | 0.94 | 0.93 to 0.94 | 2044 |
| Initial Fluent English Proficient | 0.93 | 0.92 to 0.93 | 387 |
| Reclassified Fluency English Proficient | 0.87 | 0.83 to 0.90 | 81 |
| Home Language | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 778 |
| English | 0.94 | 0.94 to 0.95 | 543 |
| Other | 0.90 | 0.86 to 0.92 | 55 |
| Spanish | 0.93 | 0.91 to 0.94 | 180 |
| Special Education Status | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 2407 |
| No | 0.94 | 0.93 to 0.94 | 2279 |
| Yes | 0.94 | 0.92 to 0.95 | 128 |
| Hispanic Ethnicity | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 16472 |
| No | 0.94 | 0.94 to 0.94 | 11841 |
| Yes | 0.95 | 0.95 to 0.95 | 4631 |
| Race | Empirical Reliability | 95% Confidence Interval | N |
|---|---|---|---|
| All | 0.94 | 0.94 to 0.94 | 13061 |
| American Indian/Alaska Native | 0.94 | 0.92 to 0.95 | 82 |
| Asian | 0.95 | 0.94 to 0.95 | 1477 |
| Black/African American | 0.92 | 0.92 to 0.93 | 1873 |
| Multiracial | 0.92 | 0.91 to 0.92 | 5336 |
| Native Hawaiian/Other Pacific Islander | 0.92 | 0.89 to 0.94 | 48 |
| White | 0.95 | 0.95 to 0.95 | 4245 |
References
Balota, David A, Melvin J Yap, and Michael J Cortese. 2006. “Visual Word Recognition.” In Handbook of Psycholinguistics, 285–375. Elsevier.
Balota, David A, Melvin J Yap, Keith A Hutchison, Michael J Cortese, Brett Kessler, Bjorn Loftis, James H Neely, Douglas L Nelson, Greg B Simpson, and Rebecca Treiman. 2007. “The English Lexicon Project.” Behavior Research Methods 39: 445–59.
Keuleers, Emmanuel, Paula Lacey, and Marc Rastle Kathleen and Brysbaert. 2012. “The British Lexicon Project: Lexical Decision Data for 28,730 Monosyllabic and Disyllabic English Words.” Behavior Research Methods 44 (1): 287–304.
Ma, Wanjing A, Adam Richie-Halford, Klint Burkhardt Amy and Kanopka, Clementine Chou, and Jason D Domingue Benjamin and Yeatman. 2023. “ROAR-CAT: Rapid Online Assessment of Reading Ability with Computerized Adaptive Testing.”
Ratcliff, Roger, Gail McKoon, and Pablo Gomez. 2004. “A Diffusion Model Account of the Lexical Decision Task.” Psychological Review 111 (1): 159–82.
Yeatman, Jason D, Kenny An Tang, Maya Donnelly Patrick M and Yablonski, Mahalakshmi Ramamurthy, Iliana I Karipidis, Sendy Caffarra, Megumi E Takada, Klint Kanopka, Michal Ben-Shachar, and Benjamin W Domingue. 2021. “Rapid Online Assessment of Reading Ability.” Scientific Reports 11 (1): 6396.