33 Validity: Dyslexia Screening and Sub-typing in Spanish
While dyslexia is a universal phenomenon that can affect readers in any language (see Chapter 32), it is important to understand that dyslexia screening may look different depending on a reader’s language environment and experiences. Screeners must be developed for a given language, not simply translated from one language to another, in order to take into account unique linguistic properties and cultural context. We detail how the Spanish assessments that make up ROAR Foundational Reading Skills - Español were developed in Chapter 13, Chapter 14, Chapter 15, and Chapter 16.
Further, the language of a reader’s educational experiences needs to be taken into account when interpreting the scores of a screener. Whether or not the reader has had reading instruction and practice in their home language has implications for how to interpret reading scores in a given language. In many cases, for multilingual readers who need support with reading in English, it is appropriate and best practice to assess in both English and their home language. Chapter 12 goes into detail on these and other considerations to take into account when determining the language of assessment and how to interpret scores for multilingual learners. Most importantly, scores must be interpreted in relation to other data sources and learning context: Section 12.4 provides vignettes that serve as useful examples for how scores can be interpreted.
33.1 Dyslexia screening based on foundational reading skills: Criterion validity in Spanish
Similar to our approach to our English assessments, (see Section 10.1), to assess sensitivity and specificity of ROAR Foundational Reading Skills - Español as an indicator of reading challenges including dyslexia, we ran two studies of criterion validity—one with a reading assessment that is among the most commonly used in schools, and one with the most widely-used measure in dyslexia research. In addition, we validated the assessments in a population of monolingual Spanish speakers whose language of reading instruction was also Spanish, as well as a population of Spanish-speaking multilingual learners in California, whose language of reading instruction varied across English-only, bilingual, and language immersion classrooms.
Criterion validity in Spanish
- A study in collaboration with 4 schools in an urban center of Colombia to examine criterion validity of ROAR-Español for students who speak Spanish as their primary language and are learning to read in Spanish. This study uses the Woodcock-Muñoz Language Survey III as the criterion measure. We use a threshold of the 25th percentile based on national norms developed with Spanish-speaking students in the United States to define students at risk of reading difficulties including dyslexia. We calculate prediction accuracy, sensitivity and specificity of ROAR-Español Foundational Reading Skills relative to this criterion.
- A study in collaboration with a large California school district that serves a large population of English Language Learners (ELLs). Students in this district completed ROAR Foundational Reading Skills measures in both English and Spanish. FAST™ earlyReading and FAST™ CBMreading risk categories were provided by the school as the criterion measures to examine whether screening in both English and Spanish improved prediction accuracy. This study is ongoing and will be completed in Spring 2025.
33.1.1 Criterion Validity Study 1: Woodcock-Muñoz
This study included students from 4 schools in an urban center of Colombia to examine criterion validity of ROAR-Español for students who speak Spanish as their primary language and are learning to read in Spanish.
33.1.1.1 ROAR-Palabra and ROAR-Frase
As described in Chapter 32, similar to how we compute prediction accuracy in ROAR-English, we begin by computing prediction accuracy, sensitivity and specificity for ROAR-Palabra and ROAR-Frase. We then examine whether additional measures lead to more accurate predictions. Finally, we examine each additional measure in isolation.
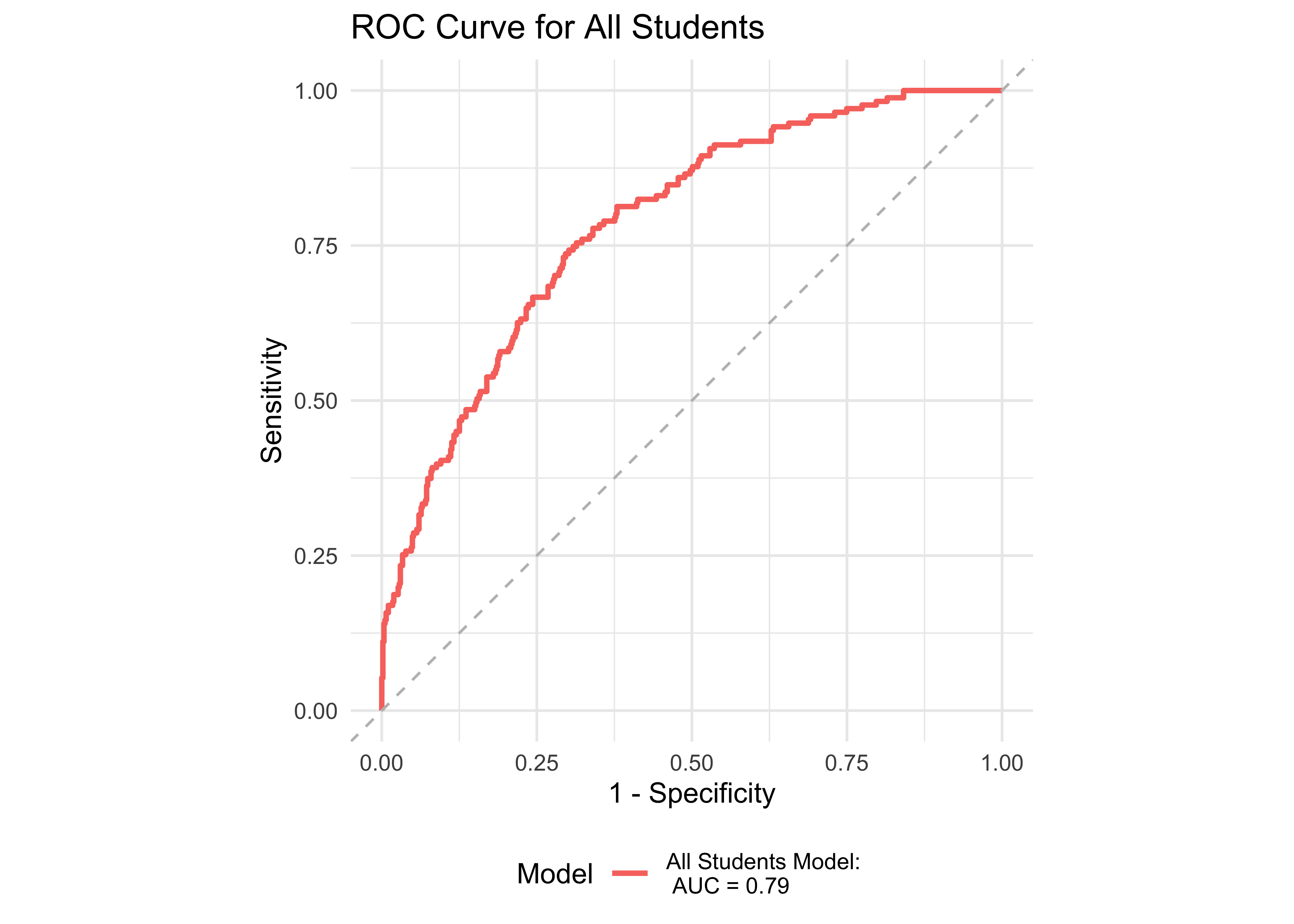
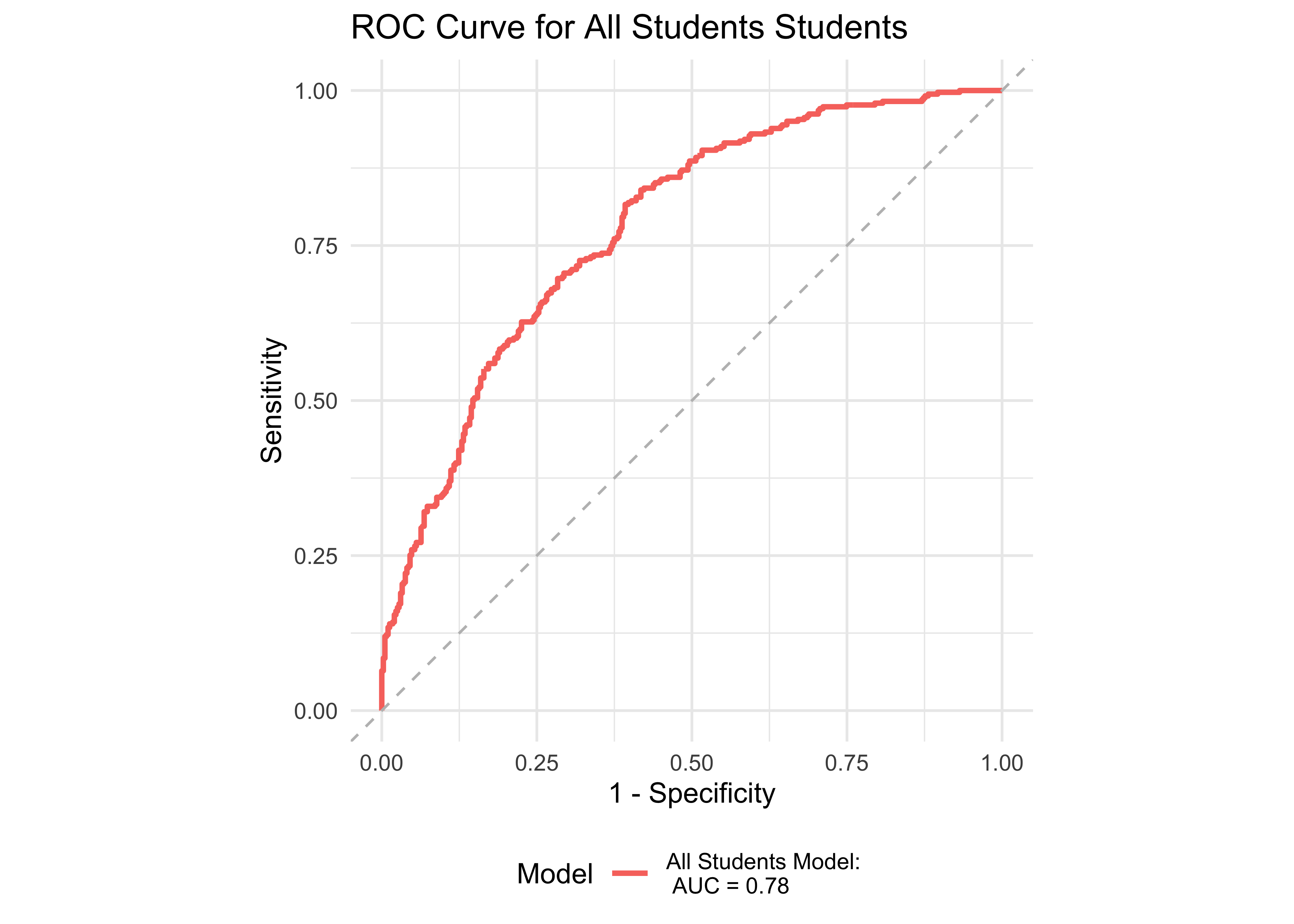
Figure 33.1 shows an ROC curve for all grades who took ROAR in Spanish computed from a logistic regression model with ROAR-Palabra and ROAR-Frase as predictors of the Woodcock-Muñoz Basic Reading Skills lower 25th percentile. Figure 33.2 shows an ROC curve for all grades who took ROAR in Spanish computed from a logistic regression model with ROAR-Palabra and ROAR-Frase as predictors of the Woodcock-Muñoz Basic Reading Skills lower 50th percentile. These two models achieved an accuracy with area under the curve (AUC) greater than 0.75 for both Woodcock-Muñoz cutoffs. Table 33.1 and Table 33.2 report sensitivity, specificity and accuracy. Best sensitivity and specificity are determined using Youden’s J statistic (Youden 1950). The optimal cut-off is the threshold that maximizes the distance to the identity (diagonal) line. The optimality criterion is: \(max(sensitivities + sensitivities)\)
| Group | AUC | Best Specificity | Best Sensitivity | Specificity (Sensitivity at 0.9) | Sensitivity at 0.9 | N |
|---|---|---|---|---|---|---|
| Lower 25th Percentile | 0.79 | 0.69 | 0.75 | 0.47 | 0.9 | 1678 |
| Group | AUC | Best Specificity | Best Sensitivity | Specificity (Sensitivity at 0.9) | Sensitivity at 0.9 | N |
|---|---|---|---|---|---|---|
| Lower 50th Percentile | 0.78 | 0.58 | 0.85 | 0.47 | 0.9 | 1678 |
33.1.1.2 ROAR Foundational Reading Skills Composite
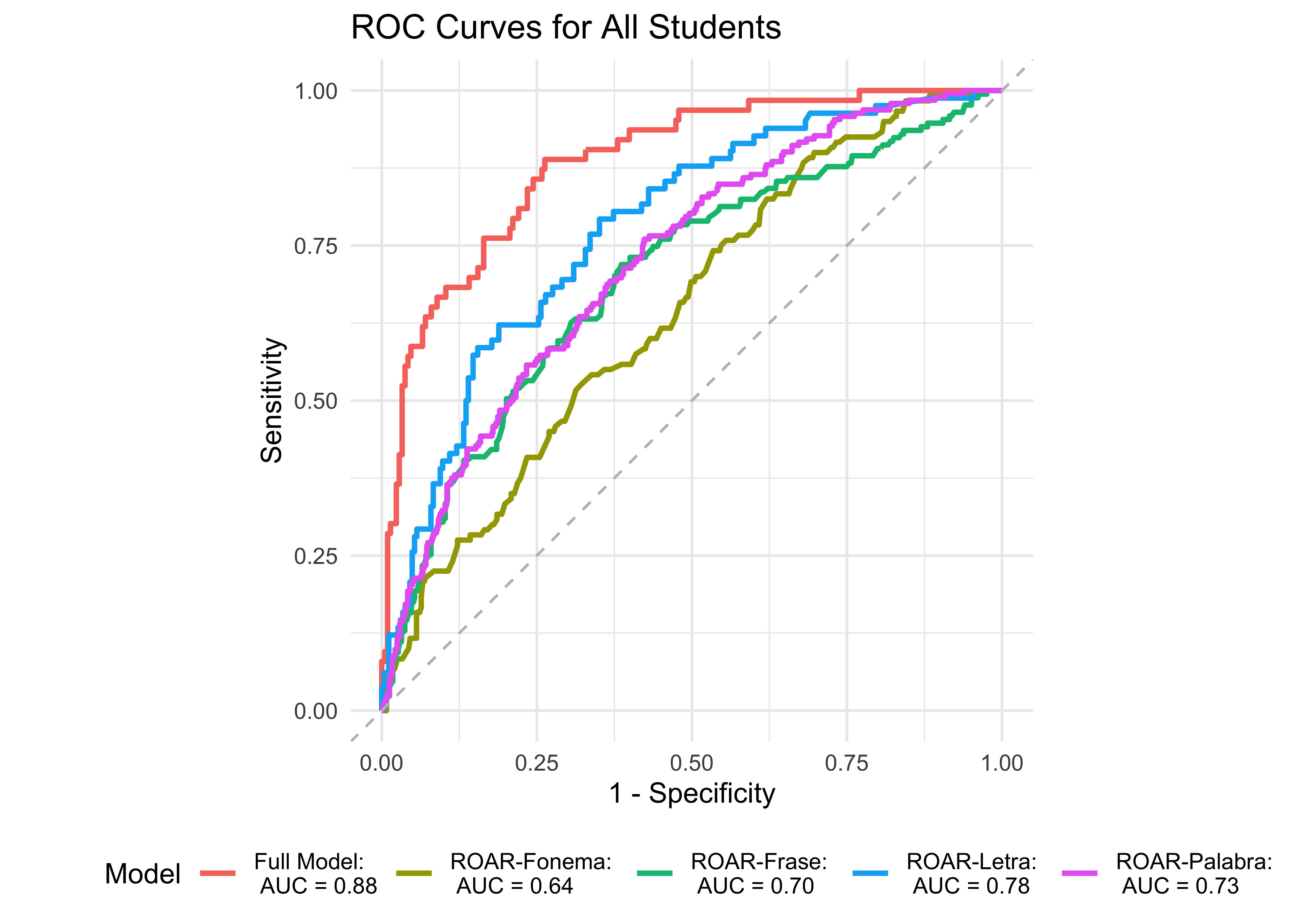
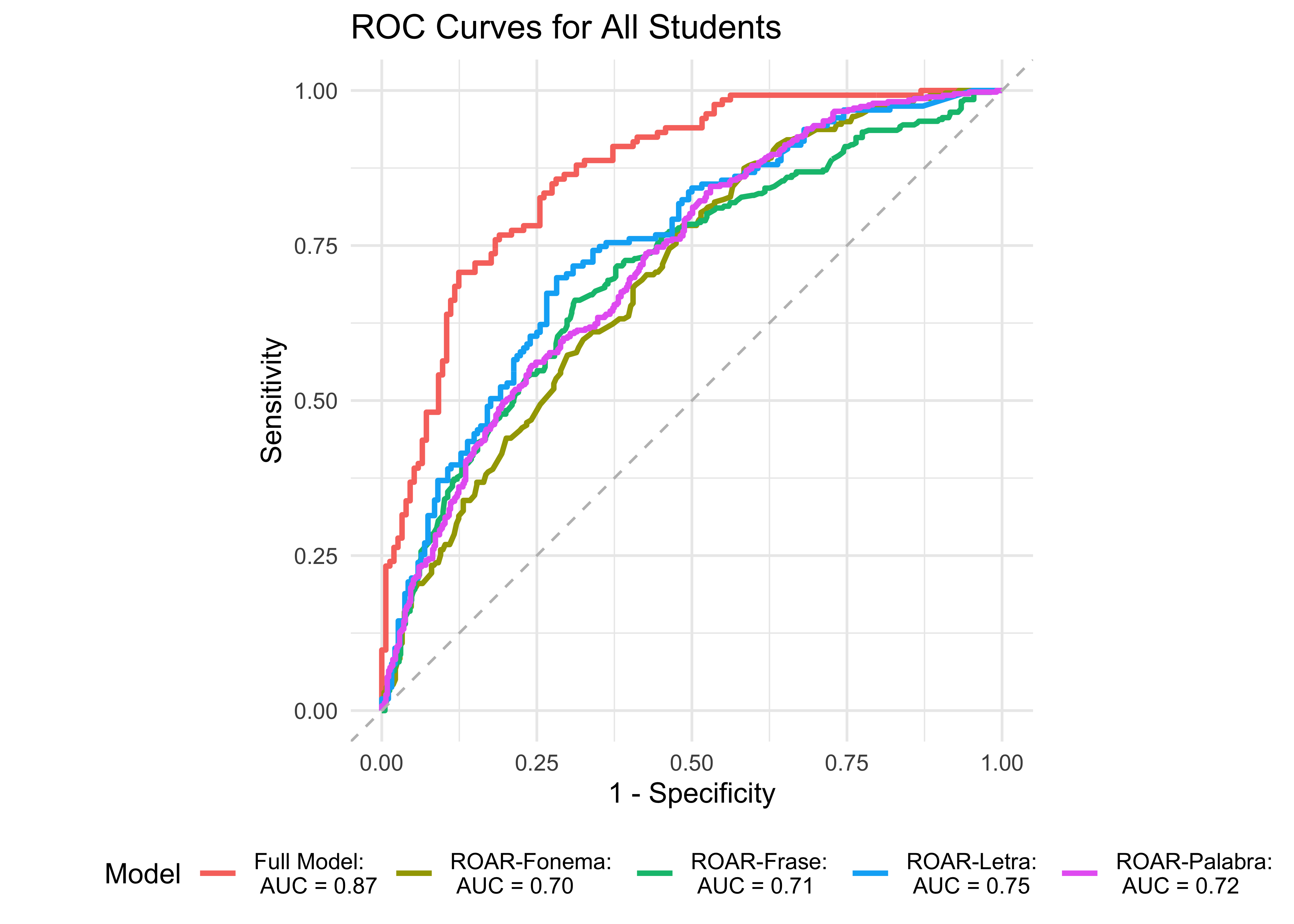
Next, we examine model accuracy based on a logistic regression model with all four ROAR measures of foundational reading skills: ROAR-Fonema, ROAR-Letra, ROAR-Palabra, and ROAR-Frase in grades K-6. Since model accuracy was lower for the simpler model with only ROAR-Frase and ROAR-Palabra, we would expect decent improvement in prediction accuracy when we add ROAR-Fonema and ROAR-Letra. Figure 33.3 shows an ROC curve for the full model predicting the Woodcock-Muñoz Basic Reading Skills lower 25th percentile with all the ROAR measures (Fonema, Letra, Palabra, and Frase) compared to models with each individual measure. ROAR-Letra and ROAR-Fonema both achieved exceptional accuracy, and the full model performed marginally better. Figure 33.3 shows ROC curves for the four models predicting the Woodcock-Muñoz Basic Reading Skills lower 50th percentile. When predicting the lower 25th and lower 50th percentile of the Woodcock-Muñoz Basic Reading Skills, the full model (ROAR-Letra, ROAR-Fonema, ROAR-Palabra, and ROAR-Frase) performs marginally better than all other models, with area under the curve (AUC) of 0.87 and 0.89, respectively.
References
Youden, William J. 1950. “Index for Rating Diagnostic Tests.” Cancer 3 (1): 32–35.